Standing out in a crowd of competitors is no easy task. But one Duke team has done just that — in math.
The Blue Devils were the only U.S.-based team to claim a top 25 finish at the 40th annual Mathematical Contest in Modeling (MCM), beating out more than 18,500 other teams from 20 countries.
Blue Devils Brandon Lu, Benny Sun and Chris Kan (L to R) finished in the top 25 out of 18,525 teams in an international math contest called Mathematical Contest in Modeling.
The team consisted of undergraduates Christopher Kan, Benny Sun, and Brandon Lu. Their task: to solve a real-world problem using mathematical modeling within 96 hours.
This year’s contestants tackled problems ranging from analyzing what gives tennis players an edge at Wimbledon, to optimizing search and rescue operations for missing submersibles.
The Duke team tackled a challenge that has vexed the fishing industry in the Great Lakes: predicting the impact of an invasive parasitic fish called the sea lamprey that can wreak havoc on native fish.
By adapting existing models from biology and biochemistry to model the sea lamprey population, the students were able to determine how to best apply treatments to rid streams of these parasites.
Two sea lampreys chewing their way into the flesh of a native lake trout of the Great Lakes. (Great Lakes Fisheries Commission)
The contest “is much more open-ended and creatively-focused than most STEM classes,” said Sun, a mathematics and computer science double major at Duke.
The participants try out different approaches to modeling the problems, and there is no one correct answer.
Sun, Kan and Lu also received the Mathematical Association of America Award for their paper. “They did a great job,” said team advisor Veronica Ciocanel, an assistant professor of math and biology who also co-organizes a local version of the contest each fall, called the Triangle Competition in Math Modeling.
In these contests, creativity, time management and writing skills are just as important as cramming on concepts.
“We realized that communication was as important as the findings themselves,” Sun said. “We spent the last two days primarily focused on writing a good paper.”
Having fun as a team is important too, Sun said. “Team chemistry can be an especially important factor in success when you are all locked in the same room for the weekend.”
Yet hundreds of schools compete each year, and this time the Blue Devilsmade it into the top three
Duke placed third out of 471 schools in North America’s most prestigious math competition, the Putnam. The top-scoring team consisted of (L to R): Erick Jiang ’26, Kai Wang ’27, and Fletch Rydell ’26.
Every year, thousands of college students from across the U.S. and Canada give up a full Saturday before finals begin to take a notoriously difficult, 6-hour math test — and not for a grade, but for fun.
In “the Putnam,” as it’s known, contestants spend two 3-hour sessions trying to solve 12 proof-based math problems worth 10 points apiece.
More than 150,000 people have taken the exam in the contest’s 85-year history, but only five times has someone earned a perfect score. Total scores of 1 or 0 are not uncommon.
Despite the odds, the Blue Devils had a strong showing this year.
A total of 3,857 students from 471 schools competed in the December contest. In results announced Feb. 16, a Duke team consisting of Erick Jiang ’26, James “Fletch” Rydell ’26 and Kaixin “Kai” Wang ’27 ranked third in North America behind MIT and Harvard, winning a $15,000 prize for Duke and each taking home $600 for themselves.
According to mathematics professor Lenny Ng, it’s Duke’s best performance in almost 20 years.
“This is the first time a Duke team has placed this high since 2005,” said Ng, who was a three-time Putnam Fellow himself, finishing in the top five each year he was an undergraduate at Harvard.
Duke students sit for an all-day math marathon.
There’s no official syllabus for prepping for the Putnam. To get ready, the students practice working through problems and discussing their solutions in a weekly problem-solving seminar held each fall.
Students serve as the instructors, focusing on a different topic each week ranging from calculus to number theory.
“They get a sense of what the problems are like, so it’s not quite as intimidating as it might be if they went into the contest cold,” said math department chair Robert Bryant.
“Not only do they learn how to do the problems, but they also get to know each other,” said professor emeritus David Kraines, who has coached Duke Putnam participants for more than 30 years.
Kraines said 8-10 students take his problem-solving seminar for credit each fall. “We always get another 10 or so who come for the pizza,” Kraines said.
The biggest difference between a Putnam problem and a homework problem, said engineering student Rydell, is that usually with a homework problem you’ve already been shown what to do; you just have to apply it.
Whereas most of the time in math competitions like the Putnam, “there’s no clear path forward when you first see the problem,” Rydell said. “They’re more about finding some insight or way of looking at the problem in a different perspective.”
Putnam problems are meant to be solvable using only paper and pencil — no computing power required. The contestants work through each problem by hand, trying different paths towards a solution and spelling out their reasoning step-by-step.
This year, one problem involved determining how many configurations of coins are possible given a grid with coins sitting in some of the squares, if those coins are only allowed to move in certain ways.
Another question required knowing something about the geometry of a 20-sided shape known as a icosahedron.
“That was the one I struggled with the most,” said Wang, whose individual score nevertheless tied him for sixth place overall out of 3,857 contestants.
A sample of problems from the 84th Putnam Competition.
The most common question he gets asked about the Putnam, Rydell said, is not so much what’s on the test, but why people take it in the first place.
This year’s test was so challenging that a score of 78 out of 120 or better — just 65% — was enough to earn a spot in the top 10.
Most of the people who took it scored less than 10%, which means many problems went unsolved.
“For days after I took the Putnam, I would think about the problems and wonder: could I have done it better this way? You can become obsessed,” said Bryant, who took the Putnam in the 1970s as a college student at NC State.
Sophomores Jiang and Rydell, who both ranked in the top 5%, see it as an opportunity to “meet people who also enjoy problem solving,” Jiang said.
“I’m not a math major so I probably wouldn’t do much of this kind of problem solving otherwise,” Rydell said.
For Rydell it’s also the aha moment: “Just the reward of when you solve a problem, the feeling of making that breakthrough,” Rydell said.
Professor Kraines’ weekly problem-solving seminar, MATH 283S, takes place on Tuesday evenings at 6:15 p.m. during the fall semester. Registration for Fall 2024 begins April 3.
Duke team wins top prize in mathematical modeling contest
Safari-goers watch a pride of lions in the Maasai Mara, a famous game reserve in Kenya. Credit: Ray in Manila, CC BY 2.0 via Wikimedia Commons
Of all the math competitions for college students, the annual Mathematical Contest in Modeling (MCM) is one of the biggest. And this year, Duke’s team took home a coveted top prize.
Undergraduates Erik Novak, ’24, Nicolas Salazar, ’23, and Enzo Moraes Mescall, ’24, represented the Blue Devils at this year’s contest, a grueling 4-day event where teams of undergraduates use their mathematical modeling skills to solve a real-world problem. The results are finally in, and the Duke team was chosen as one of the top 22 outstanding winners out of more than 11,200 teams worldwide.
Their task: to analyze some of the challenges facing a nature reserve in Kenya known as the Maasai Mara. This region is named for the local Maasai people, a tribe of semi-nomadic people who make a living by herding cattle. It’s also teeming with wildlife. Each year, more than a million wildebeests, zebras and gazelles travel in a loop from neighboring Tanzania into Kenya’s Maasai Mara Reserve and back, following the seasonal rains in search of fresh grass to eat.
Some 300,000 safari-goers also flock to the area to witness the massive migration, making it a major player in Kenya’s billion-dollar tourism industry. But protecting and managing the land for the benefit of both wildlife and people is a delicate balancing act.
The reserve relies on tourism revenue to protect the animals that live there. If tourism slumps — due to political unrest in Kenya, or the COVID-19 pandemic — desperate communities living around the park resort to poaching to get by, threatening the very wildlife that tourism depends on.
Poachers aren’t the only problem: wild animals such as lions, leopards and elephants sometimes venture into human settlements in search of food. Conservationists must strike a balance between protecting these animals and managing the dangers they pose by raiding crops or killing valuable domestic livestock.
Tourism is a mixed blessing, too. While safari-goers bring money into the region, they can also disturb the animals and pollute the Mara River, and off-road drivers can erode the soil with their jeeps.
The mission facing the Duke team was to identify ways to mitigate such conflicts between wildlife and people.
From left: Teammates Erik Novak, ’24, Nicolas Salazar, ’23, and Enzo Moraes Mescall ’24 finished in the top 0.1% in the 2023 Mathematical Contest in Modeling.
This year’s contest ran over a single weekend in February. Camped out on the third floor of Perkins library, the team of three worked 12 hours a day, fueled by a steady supply of Red Bull and poke bowls. During that time, they built a model, came up with budget and policy recommendations, and wrote a 25-page report for the Kenyan Tourism and Wildlife Committee, all in less than 96 hours.
They built a mathematical model consisting of a system of six ordinary differential equations. According to the model’s predictions, they said, it should theoretically be possible to increase the reserve’s animal populations by about 25%, reduce environmental degradation by 20%, nearly eliminate retaliatory lion killings, and cut poaching rates in half — all while increasing the average yearly flow of tourists by 7.5%.
Participating in a smaller-but-similar contest last fall, the Triangle Competition in Mathematical Modeling, helped them prepare. “It’s kind of like a practice for the MCM,” Salazar said.
Veronica Ciocanel
“They did not win that contest, but they took everything they learned and look what they did with it. I’m very proud,” said assistant professor of mathematics and biology Veronica Ciocanel, who coached the team and co-organized the Triangle competition.
In addition to finishing in the top 0.1% of competitors, the Duke team got three additional awards for their performance; the Mathematical Association of America (MAA) award, the Society for Industrial and Applied Mathematics (SIAM) prize, and an International COMAP Scholarship Award of $10,000.
The problems in these contests tend to be much more open-ended than typical coursework. “We didn’t know what the solution was supposed to be or what tools to use,” Novak said.
Modeling, computation and coding skills are certainly important, Ciocanel said. “But really what matters more is practice, teamwork, and communicating their results in a written report. Students who have a solid course background don’t need to do anything else to prepare, they just need to be creative about using what they know from the courses they already took.”
“Use what you have and work well together,” Ciocanel said. “That I think is the most important thing.”
With so many different career options in life, how do you know that you’ve found the right one for you?
Graduate students Edric Tam and Andrew McCormack, when asked what they hope to be doing in ten years, said they’d choose to do exactly the kind of work they’re doing right now – so clearly, they’ve found the right path. Tam, who obtained his undergraduate degree in Biomedical Engineering, Neuroscience and Applied Mathematics from Johns Hopkins University, and McCormack, who came from the University of Toronto with a degree in Statistics, are now 5th-year PhD students in the Department of Statistical Sciences. Tam works with Professor David Dunson, while McCormack works with Professor Peter Hoff, and both hope to pursue research careers in statistics.
Edric Tam
Andrew McCormack
Research interests
For the past five years, McCormack has been doing more theoretical research, looking at how geometry can lend insights into statistical models. The example he gives is of the Fisher information matrix, a statistical model that many undergraduate statistics majors learn in their third or fourth year.
Tam, meanwhile, looks at data with unique graphical and connectivity structures that aren’t quite linear or easily modeled, such as a brain connectome or a social network. In doing so, he works on answering two questions – how can you model data like this, and how can you leverage the unique structure of the data in the process?
What both Tam and McCormack like about the field of statistics is that, as Tam puts it, “you get to play in everyone’s backyard.” Moreover, as McCormack says, the beauty of theoretical research is that, while it’s certainly more time-consuming and incremental, it is often timeless, giving insight into something previously unknown.
On walking the research path
What does it take to be a successful PhD student? Both McCormack and Tam agree that a PhD is just a degree – anyone can get one if you work hard. But what sustains both through a career in research is a passion for what they do. Tam says that “you need inherent motivation, curiosity, passion, and drive.” McCormack adds that it helps if you work on problems that are interesting to you.
Tam, who spent some time in a biomedical engineering lab during his undergraduate years, remembers reading about math and statistics the entire time he was there, which signaled to him that maybe, biomedical engineering wasn’t for him. McCormack’s defining moment occurred in the proof-based classes he took while as an undergraduate. He initially wanted to pursue a career in finance, but he quickly became enamored by the elegant precision of mathematical proofs – “even if all you’re proving is that 1+1=2!”
“You need inherent motivation, curiosity, passion, and drive.”
Edric tam, on what it takes to pursue a career in research
Even with passion for what you do, however, research can have its ups and downs. McCormack describes the rollercoaster of coming up with a new idea, convinced that “this is a paper right here”, and then a day later, after he’s had time to think about the idea, realizing that it isn’t quite up to the mark. Tam, who considers himself a pretty laidback person, sometimes finds the Type A personalities in research, as in any career field, too intense. Both McCormack and Tam prefer to not take themselves too seriously, and both exude a love for – and a trust of – the process.
Tam, not taking himself too seriously
Reflections on the past and the future
Upon graduation, McCormack will move to Germany to pursue a post-doc before beginning a job as Assistant Professor in Statistics at the University of Alberta. Tam will continue his research at Duke before applying to post-doc programs. In reflecting on their paths that have brought them till now, both feel content with the journey they’ve taken.
Tam sees the future in front of him – from PhD to post-doc to professorship – as “just a change in the title, with more responsibility”, and is excited to embark on his post-doc, where he gets to continue to do the research he loves. “It doesn’t get much better than this,” he laughs, and McCormack agrees. When McCormack joins the faculty at the University of Alberta, he’s looking forward to mentoring students in a much larger capacity, although he comments that the job will probably be challenging and he’s expecting to feel a little bit of imposter syndrome as he settles in.
When asked for parting thoughts, both Tam and McCormack emphasize that the best time to get into statistics and machine learning is right now. The advent of ChatGPT, for example, could replace jobs and transform education. But given their love for the field, this recommendation isn’t surprising. As Tam succinctly puts it, “given a choice between doing math and going out with friends, I would do math – unless that friend is Andy!”
After a three-year hiatus caused by the COVID-19 pandemic, Duke’s student chapter of the American Society of Civil Engineers (ASCE) returned to the Carolinas in-person gathering. And they were in it to win it, taking home awards in four out of the five events in which they competed.
Duke sent seven Duke undergraduates to the symposium, which was hosted by The Citadel in Charleston, South Carolina: Leo Lee, Harrison Kendall, Arthur Tsang, Hana Thibault, Anya Dias-Hawkins, Sarah Bailey and Grace Lee.
When not going for gold, the students also attended business meetings and professional workshops related to the civil engineering profession.
(Left to right) Leo Lee, Harrison Kendall, Arthur Tsang, Hana Thibault, Anya Dias-Hawkins, Sarah Bailey, Grace Lee at The Citadel after the Symposium awards banquet.
Duke ASCE students also enjoyed networking with peers for the first time in years, meeting chapter members from other schools such as North Carolina Agricultural and Technical State University, North Carolina State University, The Citadel, Horry Georgetown Technical College, and Clemson University.
Sarah Bailey, Harrison Kendall, Anya Dias-Hawkins, and Hana Thibault before competing in the Quiz Bowl competition.
But when the lights came up, the gloves came off, and Duke’s students faced off against their peers in five competitions. Sophomore Anya Dias-Hawkins and junior Sarah Bailey earned third place for their efforts in the Geotechnical competition, where students were tasked with a real-life geotechnical design problem.
Juniors Grace Lee and Leo Lee along with senior Arthur Tsang won first place for their design in the Lightest Bridge competition, where popsicle bridges had to withstand a weight of 200 lbs.
Sophomores Anya Dias-Hawkins, Harrison Kendall and Hana Thibault also took home first place honors in the Freshmore competition, where students were tasked with designing an imaginary city. Lastly, Harrison Kendall won an individual award for his paper and presentation in the Daniel W. Mead Paper competition.
Arthur Tsang, Leo Lee, and Grace Lee standing on their winning Lightest Bridge design.
Duke ASCE is extremely excited to continue their efforts at the Carolinas symposium next year and hopes to send many more competitors. The group plans to compete in larger competitions such as Concrete Canoe next year at UNC Charlotte. With enough preparation, the students hope to advance to the national conference in 2024.
If you are interested in getting involved with Duke ASCE and/or competing in next year’s symposium, please email co-Presidents Sarah Bailey and Harrison Kendall at sarah.a.bailey@duke.edu or harrison.kendall@duke.edu.
Post by Harrison Kendall, civil engineering class of ‘25
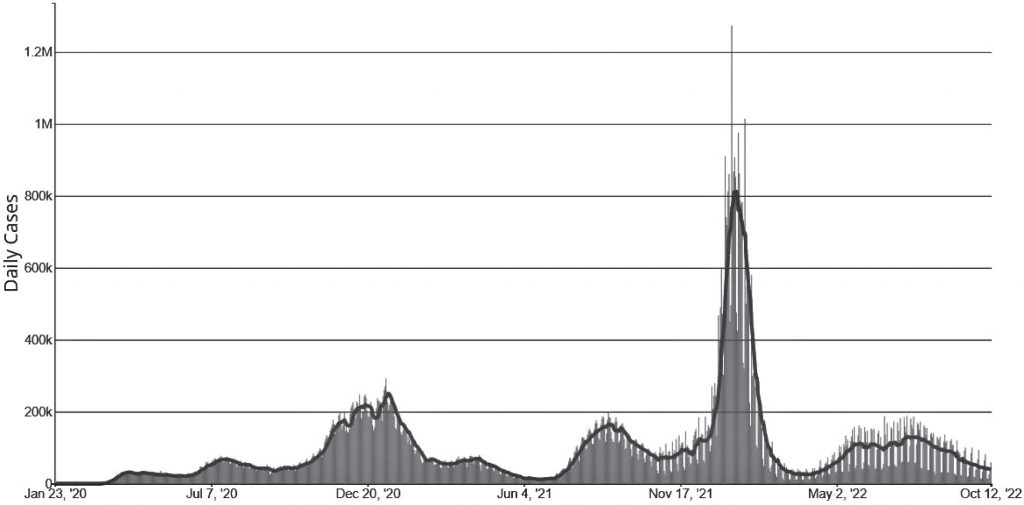
A Duke team looks at the math behind COVID’s waves as new coronavirus variants continue to emerge.Credit: @ink-drop
DURHAM, N.C. — First it was Alpha. Then Delta. Now Omicron and its alphabet soup of subvariants. In the three years since the coronavirus pandemic started, every few months or so a new strain seems to go around, only to be outdone by the next one.
If the constant rise and fall of new coronavirus variants has left you feeling dizzy, you’re not alone. But where most people see a pandemic roller coaster, one Duke team sees a mathematical pattern.
In a new study, a group of students led by Duke mathematician Rick Durrett studied the calculus behind the pandemic’s waves.
Published Nov. 2022 in the journal Proceedings of the National Academy of Sciences, their study got its start as part of an 8-week summer research program called DOmath, now known as Math+, which brings undergraduates together to collaborate on a faculty-led project.
Their mission: to build and analyze simple mathematical models to understand the spread of COVID-19 as one strain after another popped up and then rose to outcompete the others.
In an interview about their research, project manager and Duke Ph.D. student Hwai-Ray Tung pointed to a squiggly line showing the number of confirmed COVID cases per capita in the U.S. between January 2020 and October 2022.
The COVID-19 pandemic has unfolded in waves. Adapted from The New York Times, July 18, 2022
“You can see very distinct humps,” Tung said.
The COVID pandemic has unfolded in a series of surges and lulls — spikes in infection followed by downturns in case counts.
The ups and downs are partly explained by factors such as behavior, relaxation of public policies, and waning immunity from vaccines. But much of the roller coaster has been driven by changes to the coronavirus itself.
All viruses change over time, evolving mutations in their genetic makeup as they spread and replicate. Most mutations are harmless, but every so often some of them give the virus an edge: Enabling it to break into cells more easily than other strains, better evade immunity from vaccines and past infection, or make more copies of itself in order to spread more effectively.
Take the Delta variant, for example. When it first started going around in the U.S. in May 2021, it was responsible for just 1% of COVID cases. But thanks to mutations that helped the virus evade antibodies and infect cells more easily, it quickly tore across the country. Within two months it had outcompeted all the other variants and rose to the top spot, causing 94% of new infections.
“The natural question to ask is: What’s going on with the transition between these different variants?” Tung said.
For their study the team developed a simple epidemic model called an SIR model, which uses differential equations to compute the spread of disease over time.
SIR models work by categorizing individuals as either susceptible to getting sick, currently infected, or recovered. The team modified this model to have two types of infected individuals and two types of recovered individuals, one for each of two circulating strains.
The model assumes that each infectious person spreads the virus to a certain number of new people per day (while sparing others), and that, each day, a certain fraction of the currently infected group recovers.
In the study, the team applied the SIR model to data from a database called GISAID, which contains SARS-CoV-2 virus sequences from the pandemic. By looking at the coronavirus’s genetic code, researchers can tell which variants are causing infection.
Study co-author Jenny Huang ’23 pointed to a series of S-shaped curves showing the fraction of infections due to each strain from one week to the next, from January 2021 to June 2022.
When they plotted the data as points on a graph, they found that it followed a logistic differential equation as each new variant emerged, rose steeply, and — within six to 10 weeks — quickly displaced its predecessors, only to be taken over later by even more aggressive or contagious strains.
Durrett said it’s the mathematical equivalent of something biologists call a selective sweep, when natural selection increases a variant’s frequency from low to high, until nearly everyone getting stick is infected with the same strain.
“I’ve been interested in epidemic modeling since the end of freshman year when COVID started,” said Huang, a senior who plans to pursue a Ph.D. in statistics next year with support from a prestigious Quad Fellowship.
They’re not all typical math majors, Durrett said of his team. Co-author Sofia Hletko, ’25, was a walk-on to the rowing team. Laura Boyle ’24 was a Cameron Crazie.
For some team members it was their first experience with mathematical research: “I came in having no idea what a differential equation was,” Boyle said. “And by the end, I was the person in the group explaining that part of our presentation to everyone.”
Boyle says one question she keeps getting asked is: what about the next COVID surge?
“It’s very hard to say what will happen,” Boyle said.
The teams says their research can’t predict future waves. Part of the reason is the scanty data on the actual number of infections.
Countries have dialed back on their surveillance testing, and fewer places are doing the genomic sequencing necessary to identify different strains.
“We don’t know the nature of future mutations,” Durrett said. “Changes in people’s behavior will have a significant impact too.”
“The point of this paper wasn’t to predict; rather it was to explain why the waves were occurring,” Huang said. “We were trying to explain a complicated phenomenon in a simple way.”
This research was supported by a grant from the National Science Foundation (DMS 1809967) and by Duke’s Department of Mathematics.
CITATION: “Selective Sweeps in SARS-CoV-2 Variant Competition,” Laura Boyle, Sofia Hletko, Jenny Huang, June Lee, Gaurav Pallod, Hwai-Ray Tung, and Richard Durrett. Proceedings of the National Academy of Sciences, Nov. 3, 2022. DOI: 10.1073/pnas.2213879119.
Francis Su, Ph.D., visited Duke to talk about math. He began by talking about art.
Su, a mathematician and professor at Harvey Mudd College, displayed “Hope,” an 1886 painting by George Frederic Watts. He asked the audience to look at it, really look at it, and think about what’s happening in the painting. At first glance, it shows a blindfolded woman holding a wooden object. She seems to be in pain. But the more time we spend looking, the more we notice. We might notice that there’s a single star above her. We might notice that the wooden object is a lyre with only one string left attached. We might notice, too, that the woman is plucking that final string and straining to hear its music.
If we take the time to explore the history of the painting, we might learn that Martin Luther King, Jr., talked about the same painting in a sermon. Su quoted a line from that sermon: “Who has not had to face the agony of blasted hopes and shattered dreams?” We find beauty in art, and often we find it relatable as well. Art invites us to look closer, to wonder, to feel, to ask questions, to imagine.
“Why,” Su asks then, “don’t we approach mathematics the way that we approach art?”
Whether we consider ourselves “math people” or not, we rarely if ever hear mathematics discussed as an affirmation of human virtues and desires—love, beauty, truth, the “expectation of enchantment.” Su wants to change that. In his book “Mathematics for Human Flourishing” and in his talk at Duke, he envisions mathematics as beautiful, inclusive, and accessible to anyone.
Along with the painting “Hope,” Su’s first slide shows a quote by Simone Weil: “Every being cries out silently to be read differently.” Simone Weil, according to Su, was a “French religious mystic” and “widely revered philosopher,” but she also had a deep interest in math. Her older brother, André Weil, was an influential mathematician whose mathematical achievements often overshadowed her own. In a letter to a friend published posthumously in the book “Waiting for God,” Simone Weil wrote: “I did not mind having no visible successes, but what did grieve me was the idea of being excluded from that transcendent kingdom to which only the truly great have access and wherein truth abides.” Su sometimes wonders how Simone’s relationship to mathematics would have been different if André had not been her brother. Again, “Every being cries out silently to be read differently.” According to Su, when Simone Weil speaks of “reading” someone, she means “to interpret or make a judgment about them.”
Su has a friend, Christopher Jackson, who is an inmate in a high-security prison, serving a thirty-two year sentence for involvement in armed robberies as a teenager. When you think about people who do math, Su asks, would you think of Chris? “We create societal norms about who does math,” and Chris doesn’t fit those norms. And yet he has been studying mathematics for years. After studying algebra, geometry, trigonometry, and calculus while in prison, he sent a letter to Su requesting help in furthering his mathematics education. The two men still correspond regularly, and Chris is now studying topology and other branches of mathematics.
“Every being cries out silently to be read differently.”
Why do math in the first place? Just as you can take your car to a mechanic without fully understanding how it works yourself, we might think of math as “only for the elite few” or perhaps as “a means to an end,” a tool “to make you ‘college and career ready.’” Su sees it differently. He views math in terms of human flourishing, “a wholeness of being and doing.” He points to three words from other languages: eudaemonia, a Greek term for “the overarching good in life”; shalom, a Hebrew word often used as a greeting and roughly translated as “peace”; and salaam, an Arabic word with a similar meaning to shalom.
“What attracts me to music,” Su says, “isn’t playing scales over and over again.” But once you “experience a symphony,” you might see the value in playing scales. Can we learn to think of math the same way? Here, Su quoted mathematician Olga Taussky-Todd: “The yearning for and the satisfaction gained from mathematical insight brings the subject near to art.”
Beauty and awe probably aren’t the first words that come to mind when most of us think of math, but Su believes math can unlock “transcendent beauty.” He references a quote by C.S. Lewis: “the scent of a flower we have not found, the echo of a tune we have not heard, news from a country we have never yet visited.” That is what math at its best can do for us. It can help us see the big picture and realize that we’re “just scratching the surface of something really profound.”
“Math is not a single ‘ability,’” Su says. “In reality, math is a multi-dimensional set of virtues.” When learning or teaching math, we often focus more on skills like recalling facts and algorithms, factoring polynomials, or taking a derivative. But Su believes more important lessons are at play: virtues like persistence, creativity, a thirst for deep knowledge, and what he calls the expectation of enchantment. And, he says, employers are often much more interested in virtues than in skills. “If you want to be really practical about this—and I don’t, with mathematics, but if you do—then it’s actually the virtues that are more important than the skills,” Su says.
One basic human desire that Su believes math can help fulfill is the desire for truth, which, in turn, can help build virtues like a thirst for deep knowledge and the ability to think for oneself, which can help us figure out what’s true instead of just blindly trusting authorities. “Truth is under attack,” Su says. “Misinformation is everywhere.” Su wants to teach his students “to think, to be ‘that person who doesn’t need to look at the Ikea instructions.’” But he also wants them to view math as more than just a means to an end. “It’s my responsibility to help my students remember the beauty” in math and to understand that their dignity as human beings isn’t dependent on their grades.
Along with truth and beauty, he believes math can and should bring opportunities for exploration and discovery. “My role isn’t to be a teacher,” he says. “My role is to be a co-explorer.” He recalls his own excitement when he first saw a Menger cube, or Menger sponge, cut along its diagonal. The resulting cross-section is beautiful and, yes, enchanting. “What would it look like for classrooms to be like that?” During the pandemic, Su started adding more reflection-focused questions to his exams, questions like “Consider one mathematical idea from the course that you have found beautiful, and explain why it is beautiful to you.” Even more traditional math questions can be phrased in an “exploratory” way. Su gives the example of a question that asks students to make two rectangles, one with a bigger perimeter and one with a bigger area.
Another desire or virtue important in the field of mathematics is justice. Su wants math to be accessible to all, but not everyone has had positive experiences with math or feels like they belong there. As an analogy, Su talks about receiving dishes from a “secret menu” when visiting certain Chinese restaurants with friends who are fluent in Chinese. When he goes there on his own and requests the “secret menu,” however, he is sometimes turned away or told that he wouldn’t like those dishes. “Are people side-by-side in the same restaurant having different experiences” in math, too? “Who are you to say they do or don’t belong in mathematics?”
Even Su himself hasn’t always had wholly positive experiences in math. One of his professors once told him he didn’t “have what it takes to become a successful mathematician,” and he almost quit his Ph.D. program. Instead, he switched to a different advisor who had encouraged him to stick with it. Meanwhile, he surrounded himself with people who could remind him why he loved math. Math as a field can be competitive, but “if you think of mathematics as human flourishing… then that’s not a zero-sum game anymore.”
In Su’s words, “we’re all math teachers” because “we all pass on attitudes about math to others.” He says studies show that parents can pass on “math anxiety” to their kids. But Su encourages people to “believe that you and everyone can flourish in mathematics.” Simone Weil. Christopher Jackson. And you.
“My name is Meg Stalter I’m 5’7 I’m living in LA and a fun fact about me is something bad happened to my cousin.”
As made evident by her Twitter profile, my favorite comedian, Megan (“Meg”) Stalter, knows how to make an introduction. Stalter is best known (as far as I know) for her role in the HBO comedy “Hacks,” in which she plays Kayla (whoever that is).
I do not have a Twitter account and I have never seen the show. While we are talking about me, I will explain that I do not really watch TV, with the one exception of West Wing.
Since we are still talking about me, you should know that I fibbed. There are two exceptions. The other one is Grantchester, a Masterpiece Mystery about a hot priest who solves crime (but that was sort of a given, no?).
I share Stalter’s bio for a few reasons. For starters, it makes me smile, and sharing a smile is a tried-and-true way to score a friend (cha-ching!).
Meg Stalter once again proved her knack for making a first impression at her Emmy’s debut
On top of that, it is a good example of someone who knows how to make a first impression. I expect to have made a great impression by the time I finish this, but to ensure things got started on the right foot, hedging my bets if you will, I thought it best to leave the preamble to someone at the top of the trade.
Stalter’s bio also proves a simple point; it is not merely what you say that counts, but how you say it.
I am something of a sub-par reader. I love to read, it is just not my biggest strength (doesn’t mean it can’t be (growth mindset)! Just facing today’s facts). I don’t think I read enough as a child, so now I am slow and I usually fall asleep.
But I get by. I power through my class readings, I keep a book on my bedside table, and I get my news through the radio (that and two free tickets to the Hoppin’ John’s Fiddler’s Convention–it pays to be tuned into WUNC on Saturday nights at 10. Cha-ching!).
This relationship with reading influences my writing style. When I write, I try to keep my readers awake. Not with what I write — I have full faith in the topic at hand’s capacity to speak for itself — but with the way I write it.
My past experience writing for a published paper was in high school, where I spent four years as co-editor of the “Hustle and Bustle” page. I authored a satirical advice column in which troubled high schoolers (me) could send their personal woes to someone who would publish them for the whole school to read (also me). I like writing as a secondary form of chatting.
My senior year, I retitled my column “Dear Addy,” after the well-known advice column “Dear Abby.”
And so it is with this laudable writing background that I report to you on the groundbreaking discoveries from one of the top research universities in the U.S.
Why write for a research blog? Research is interesting. Research makes the world go round. Just ask a freshman. They all came here for the “research opportunities,” as did all the other freshmen at all the other universities.
Before I sign off, I will let you know where you might catch me in my free time. This is a key element of the standard student bio, and I am prone to severe FOMO, so let me get right to it.
I am a sophomore from Hickory, North Carolina hoping to major in Public Policy and minor in Math. In my free time you might catch me listening to NPR, jogging, potting, singing to myself, making a smoothie, telling people about my smoothie, spamming my contacts for an ice cream date, or for the not-so-lucky, trying my best at Appalachian-style fiddle.
What lies at the intersection of mathematics and biology? Freshly-minted math PhD Ruby Kim and her work on mathematically modeling human dopamine cycles.
Ruby Kim, recent Duke PhD graduate
Kim’s work has centered around her creation of a math model to predict how a person’s dopamine levels ebb and flow over the course of a day “to understand the general mechanics of how disruptions in the (biological) clock lead to disruptions in dopamine.”
She said there is a pretty long history of mathematicians using differential equations to see how different clock genes and proteins change over the course of a day’s circadian cycle. Yet, no previous models have connected the circadian clock – controlled by the brain’s suprachiasmatic nucleus – to dopamine levels. And Kim tells me that work suggesting dopamine changes throughout the day are likely controlled by the internal circadian clock itself is “relatively new.”
The first step in Kim’s work was validating scientists’– or “experimentalists,” as Kim dubs them – hypotheses about dopamine and dopaminergic enzyme cycling.
Many physiological processes are controlled via circadian rhythms and the internal clock in humans, as well as other organisms.
“But I’d like this work to help experimentalists go one step further and be able to test out hypotheses more easily.” For example, Kim says that her model has the potential to reveal other fascinating phenomena, such as how drug treatments or different genetic mutations may impact circadian rhythm or dopamine. This is thanks to the multifaceted layers of Kim’s model.
“From a mathematical perspective, the math model is very interesting. It has a lot of interesting dynamics,” she says. “Not only does it show nice, 24-hour rhythms, it shows both steady state behavior… but then also behavior that’s really wild – something called quasi-periodic behavior, where the internal clock is significantly different than the external 24-hour light-dark cycle.”
“This leads to oscillatory behavior that’s not periodic,” she says. These sorts of quasi-periodic behaviors have been observed in experiments and misunderstood, but they can be computed.
Kim emphasized the experimental and clinical implications of her work. Dopamine is involved in learning and motivation and is also linked a plethora of psychiatric conditions like Parkinson’s, ADHD, and schizophrenia. “Patients with these conditions often also experience circadian disruptions,” Kim says. “That’s a pretty big symptom.”
Kim began her academic career in her home state of California at Pomona College as a pre-med math major. “I had always been intrigued by human physiology. And math was one of the subjects I was also pretty drawn to. I just didn’t appreciate it much because throughout high school and the beginning of undergrad, I didn’t see any direct applications,” Kim told me.
The marriage of her love for math with her intrigue in biology actually began at Duke when Kim attended a mathematical biology workshop during the summer after her sophomore year. “I had never heard of math biology before that.”
After working on a brief project to model sleep apnea in infants at the workshop, Kim returned to California and took up math modeling courses in her following semesters of undergrad. One of her professors, Ami E. Radunskaya, PhD, was extremely supportive and introduced Kim to a lot of “cool biological problems.” Kim went on to do research with Radunskaya, modeling tumor-immune interactions. This experience, Kim says, “kind of just threw me into academia.” The project gave way to an undergraduate thesis with Radunskaya that analyzed the long-term behavior of this tumor growth and treatment model.
Radunskaya then suggested that Kim pursue grad school. “I kind of applied on a whim,” Kim said, “It wasn’t something I had specifically imagined for myself.” Kim mentioned how no one from her home community had really ever gone to grad school and so it was not something she had ever “explicitly” thought about before.
An abstract of Radunskaya’s work on mathematical modeling and understanding tumor-immune interactions to address cancer.
In her search for a graduate program, Kim applied to math programs, as well as those that were interdisciplinary. “I ended up choosing Duke because I really liked my advisor,” Kim told me. While Kim’s advisor Michael Reed, PhD “does a lot of interesting math,” Kim wanted to work with him because math isn’t his focus – understanding “really complex biological systems using mathematical language is.”
“A lot of times you see people who do things at the intersection of math and biology that are more motivated from a mathematical standpoint … that’s just not what I’m interested in personally. I’m very interested in finding an interesting biological problem and then applying whatever mathematical tools I have.”
While at Duke, Kim was foundational to founding the university’s chapter of the Association for Women in Math (AWM). During her undergrad, Kim “had a really great experience with AWM,” finding both a community of women mathematicians and a network of women professors who were involved in the chapter.
At Duke, there wasn’t a chapter “but quite a few people who were interested in starting and being part of one.” This organization, which is open to people of any gender identity, heads mentorship programming that brings undergrads, grad students, postdocs, and professors together, organizes conferences, and contributes to their central focus of community building in math.
Example flyers of the events organized by the Duke chapter of the Association for Women in Mathematics.
Outside of her research, Kim spends most of her free time taking care of foster pups, which she describes as “extremely rewarding but also very tiring.” Her most recent foster, a four-month-old puppy, eavesdropped on our interview as he took a nap.
This fall, Kim will begin a post-doc with the University of Michigan’s math department as she “wanted to keep studying circadian rhythms with faculty who are really great in that area.”
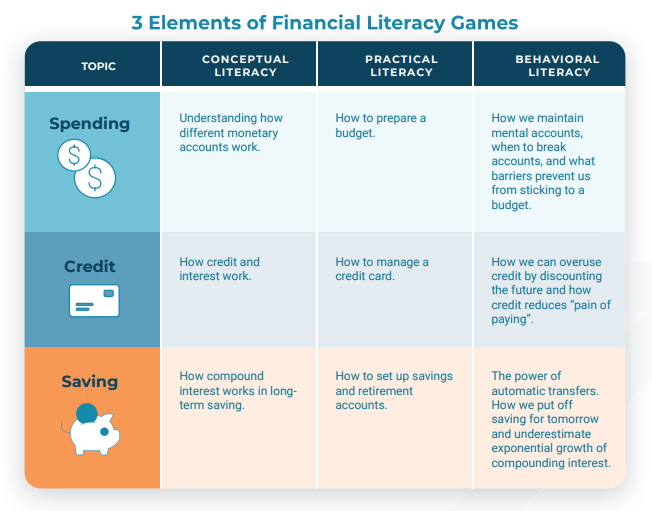
Institute for Consumer Money Management, and Duke University’s Center for Advanced Hindsight.
Intending to do the right thing doesn’t always lead to actually doing it, a tendency formally known as the “intention-behavior gap.” We can intend to go to bed early and still go to bed late. We can want to exercise and still choose not to. We can recognize the importance of saving extra money and still choose to spend it instead. So why is it so hard to change our behavior? Because, says Jonathan Corbin, Ph.D., “brains are weird” and “the world is difficult.”
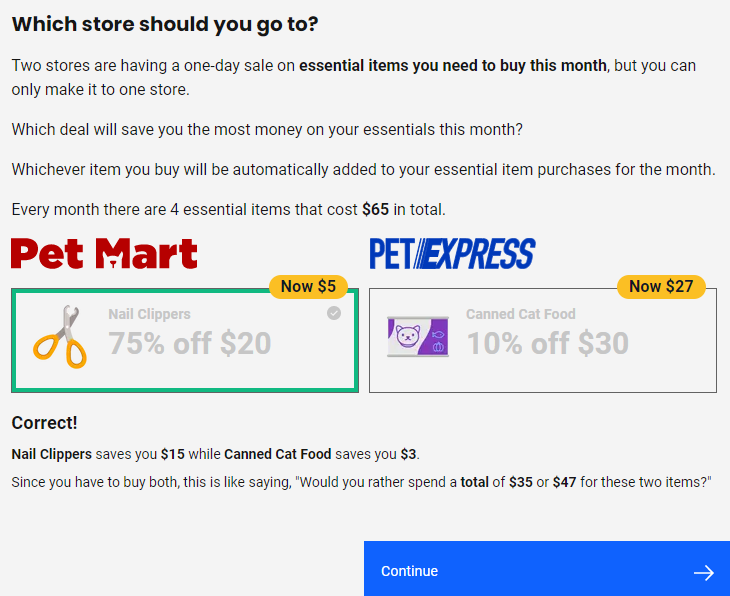
Corbin is a senior behavioral researcher at the Center for Advanced Hindsight at Duke University. The Center for Advanced Hindsight recently partnered with NOVA Labs, Thought Cafè, and the Institute for Consumer Money Management to create the NOVA Financial Lab, a group of financial literacy games targeted at adolescents and emerging adults. In each game, players practice managing money while taking care of a pet. You may never have to sneak a cat into a concert or prepare a retirement plan for a dog in real life, but you will need to understand concepts like budgeting, interest, and debt. “What we hope people start to do,” Corbin says, “is really think about, ‘What decisions should I make now to make better decisions later?’”
Essentially, “Money spent now is money that can’t be spent later.” As intuitive as that might seem, “The way we think about money is relative, and it’s not linear.” When you’re already spending thousands of dollars on a car, for instance, an extra five hundred dollars for a feature you may or may not need “feels like a very small amount of money,” but in a different situation, its value can seem higher. How many times, Corbin points out, could you go out to eat with five hundred dollars?
There are three games: Shopportunity Cost, Budget Busters, and Exponential Potential. (“One of the people from PBS helped us come up with these cute names,” Corbin says.) They each involve different skills, but they all focus on “financial literacy from a behavioral science perspective.” Players have to contend with both external obstacles and common behavioral biases to make financial decisions for a pet. “I always choose the dog,” Corbin adds, “but I understand other people might choose the cat.” (I chose the cat.)
The first game, Shopportunity Cost, focuses on short-term financial planning. It involves dressing a pet up like a person in order to sneak them into a concert for the night. “You have to make decisions that optimize the pet’s happiness while also being able to make it to the concert and back home,” but you have a limited amount of money to spend. If you spend too much money too soon, you’ll run out, but if you’re too frugal, your pet won’t enjoy the evening. As goofy as the concert scenario is, it introduces players to an important concept known as opportunity cost, which refers to the potential benefits we miss out on when we choose one alternative over another. Say you’re debating between a $50 outfit and a $30 one. The opportunity cost of choosing the more expensive outfit is $20, but shoppers don’t always consider that. “Opportunity cost neglect is the simple idea that when we’re faced with financial decisions, we tend not to consider alternative uses for that money.” Reframing the $30 outfit as “a $30 dress that I’m okay with plus 20 extra dollars” that could be spent elsewhere might lead you to choose the cheaper outfit. Or it might not. “Sometimes you want the $50 outfit, and that’s perfectly fine… but a lot of the time that might not be the right decision.” Like many things, taking opportunity cost into account is a balancing act. “We shouldn’t obsess over every possible opportunity that there is,” Corbin cautions, but “consider[ing] opportunity costs can lead to better financial decisions.”
Budget Busters, meanwhile, involves medium-term planning. Players have to manage checking, credit, and savings accounts while caring for their pet over a six-month period. Along with purchasing essential and non-essential items to attend to their pet’s basic needs and happiness, players have to contend with unforeseen circumstances like medical emergencies. The game introduces people to the 50-30-20 rule, a budgeting concept that involves devoting 50% of income to essentials, 30% to non-essentials, and 20% to savings. Budget Busters also explores the principle of mental accounting, the idea that aside from formal budgets, we have “categories in our head” that change our perception of money. “Let’s say you get birthday money from your relative. That money tends to be a different kind of spending money to you than money you get from your paycheck,” Corbin explains, because “money feels different in different contexts.”
There are parallels in Budget Busters. Sometimes players receive unexpected windfalls like gifts or prizes. (My cat won $40 for being “Best in Show” at the local pet pageant.) Players get to decide whether to use the extra money on a “fun” item for their pet or put it into savings. Corbin says “gift money” is a classic example of a misleading mental account. “We tend to overspend… because it feels like it’s not even our money in a way.” In reality, though, money has “fungibility,” meaning it’s “exchangeable… across any account.” In other words, “money is money,” regardless of where it comes from. A $10 bill, for instance, can be exchanged for two fives without changing its value. (Non-fungible tokens, or NFTs, lack this property. “You can’t exchange the picture of a cat you bought from the internet for Chipotle.”) Like Shopportunity Cost, Budget Busters focuses on both traditional financial concepts and common behavioral tendencies that affect decision-making. “None of these things are necessarily bad,” Corbin emphasizes, “but they’re things that one should be aware of… when that natural proclivity may be swaying them in the wrong way.”
Budget Busters, which focuses on monthly budgeting, also encourages players to look closely at discounts when shopping. “Sometimes the discount that looks really good from a percentage-off perspective isn’t actually the better discount” in terms of overall budgeting and total amount of money saved, Corbin warns.
The last game, Exponential Potential, explores concepts like compound interest, debt, and investment. The premise of the game involves traveling back in time to balance debts and investments. The goal is to make your pet a millionaire. By showing players how investment decisions can affect future net worth, the game seeks to increase understanding of processes involving exponential growth. Exponential Potential introduces the concept of exponential growth bias. According to Corbin, “We tend to underestimate things that grow exponentially.” He cites the coronavirus pandemic as an example: “Even the people who were making the graphs of Covid’s growth… it’s really hard for them to figure out how to show that to people.” Log-transformed graphs are one option, but they can be deceptive by making the slope look flatter. Similarly, when dealing with exponential growth in the financial world, “People are going to underestimate how badly they’re going to get burned” by debt, but they may also underestimate how much they’ll benefit by saving for retirement.
With compound interest, for instance, “The interest gets applied both to principle and to interest from the last time, and that’s where exponential growth happens.” In the game, players have the opportunity to adjust how much money to put toward paying off debts, investing, and saving for retirement each month. Then they travel decades into the future to see how their decisions have affected their pet’s net worth. “We’re hoping that that kind of feedback allows you to think through… what you might have done wrong and try to correct,” Corbin says. Once again, though, raw numbers aren’t the only factor at play. “We just want people to understand what the optimal way to do this is, and if there’s a better way for them to do that psychologically, that’s fine.” Debt account aversion, for example, refers to the fact that people want to have fewer debt accounts, meaning they are often eager to pay off accounts in full when they can. Some financial advisers suggest that “because they think it’ll get the ball rolling and you’ll be more likely to pay off the next one.” According to Corbin, there isn’t a lot of evidence for that, and sometimes paying everything off at the outset isn’t ideal. For instance, “It is optimal to start thinking about retirement as soon as you can… but if you’re delaying putting money into retirement because you’re so concerned with your student loan debt,” that can be problematic. Still, Corbin understands the appeal of closing debt accounts. “I am risk-averse, which means if I have a debt I’m probably going to put more money toward that debt that I necessarily should given what the interest rates are and what I could potentially make by investing that money instead.” Financially speaking, “There’s a decent likelihood that I should just pay the minimum on my mortgage… [but] I’ve decided I’m willing to trade off those future gains for the peace of mind that if something goes wrong… I’ll be ahead on my mortgage payment.” Even in Exponential Potential, the right choices aren’t always clear-cut. Corbin describes it as a “sandbox approach” where players are given more opportunity to play around. “This is the trickiest game because there’s no perfect answer for anything,” he says. “Everything has risk.”
Another bias that can affect our financial decisions is known as present bias, the tendency to discount the future in favor of the present. Corbin offers the everyday example of staying up too late. “Nighttime Me wants to stay up and read…. Morning Me is going to be really ticked off at Nighttime Me when they’re exhausted and don’t want to get up.” Research suggests that people can have a harder time identifying with their future selves. That can easily affect our financial decisions, too. “I’m going to let future me worry about that. That guy. Whoever that is.” However, “If you can get people to identify more with that person,” they can sometimes make better decisions. Ultimately, “The game isn’t trying to force people to become investment robots.” We are biased for the present because we live in it, and that’s normal. The purpose of the game is simply “to nudge people… to worry just a little more about the future.”
“Money is basically for safety, security, and happiness,” Corbin says. The ultimate objective is to balance needs, wants, and savings to achieve those three goals both in the present and the future.



































{kind=link}
{kind=link}