Collaborating with a colleague in Shanghai, we recently published an article that explains the mathematical concept of ‘in-betweening,’in images – calculating intermediate stages of changes in appearance from one image to the next.
Our equilibrium-driven deformation algorithm (EDDA) was used to demonstrate three difficult tasks of ‘in-betweening’ images: Facial aging, coronavirus spread in the lungs, and continental drift.
Part I. Understanding Pneumonia Invasion and Retreat in COVID-19
The pandemic has influenced the entire world and taken away nearly 3 million lives to date. If a person were unlucky enough to contract the virus and COVID-19, one way to diagnose them is to carry out CT scans of their lungs to visualize the damage caused by pneumonia.
However, it is impossible to monitor the patient all the time using CT scans. Thus, the invading process is usually invisible for doctors and researchers.
To solve this difficulty, we developed a mathematical algorithm which relies on only two CT scans to simulate the pneumonia invasion process caused by COVID-19.
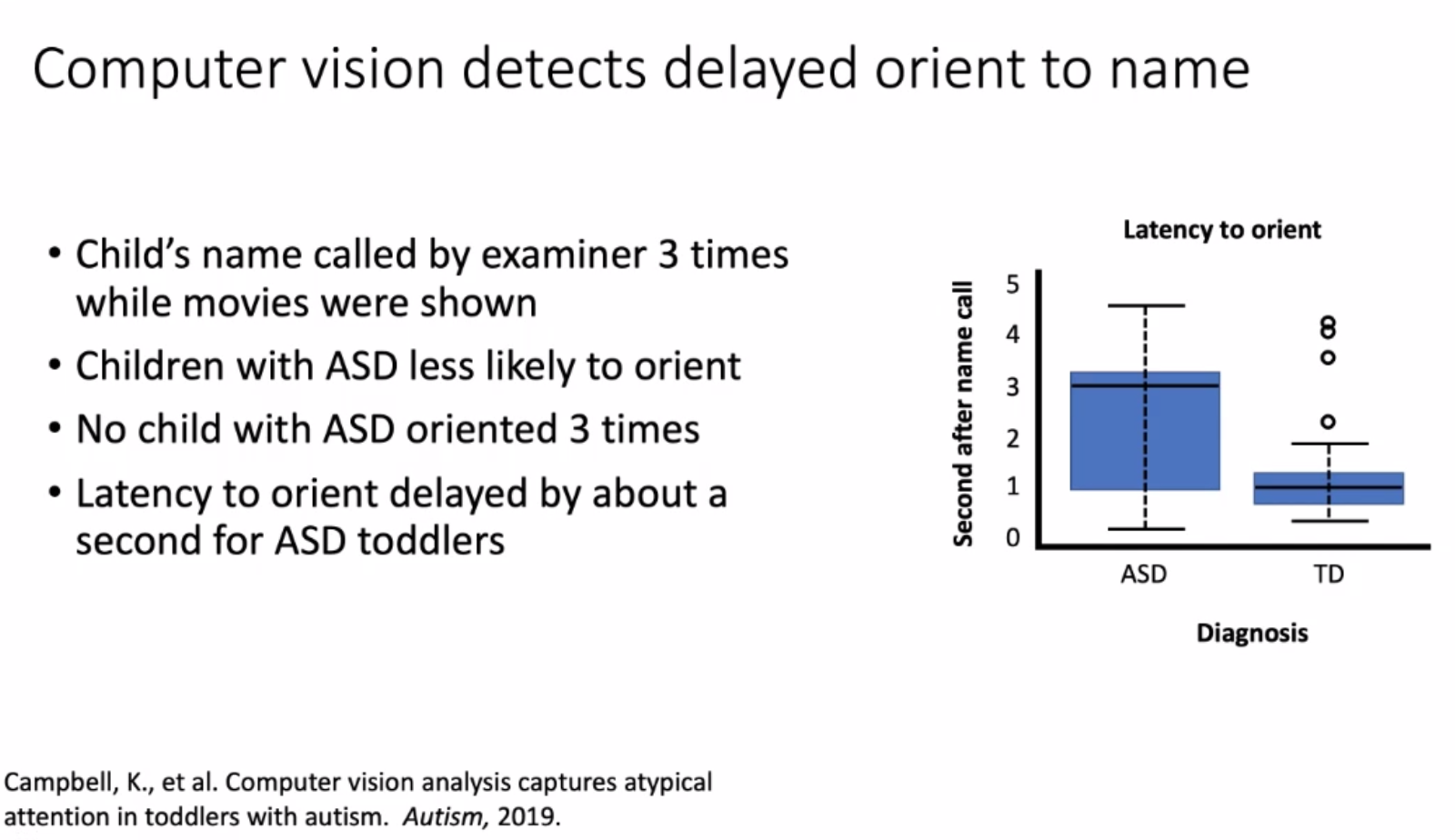
We compared a series of CT scans of a Chinese patient taken at different times. This patient had severe pneumonia caused by COVID-19 but recovered after a successful treatment. Our simulation clearly revealed the pneumonia invasion process in the patient’s lungs and the fading away process after the treatment.
Our simulation results also identify several significant areas in which the patient’s lungs are more vulnerable to the virus and other areas in which the lungs have better response to the treatment. Those areas were perfectly consistent with the medical analysis based on this patient’s actual, real-time CT scan images. The consistency of our results indicates the value of the method.


Part II. Solving the Puzzle of Continental Drift
It has always been mysterious how the continents we know evolved and formed from the ancient single supercontinent, Pangaea. But then German polar researcher Alfred Wegener proposed the continental drift hypothesis in the early 20th century. Although many geologists argued about his hypothesis initially, more sound evidence such as continental structures, fossils and the magnetic polarity of rocks has supported Wegener’s proposition.
Our data-driven algorithm has been applied to simulate the possible evolution process of continents from Pangaea period.
The underlying forces driving continental drift were determined by the equilibrium status of the continents on the current planet. In order to describe the edges that divide the land to create oceans, we proposed a delicate thresholding scheme.
The formation and deformation for different continents is clearly revealed in our simulation. For example, the ‘drift’ of the Antarctic continent from Africa can be seen happening. This exciting simulation presents a quick and obvious way for geologists to establish more possible lines of inquiry about how continents can drift from one status to another, just based on the initial and equilibrium continental status. Combined with other technological advances, this data-driven method may provide a path to solve Wegener’s puzzle of continental drift.


The study was supported by the Department of Mathematics and Physics, Duke University.
CITATION: “Inbetweening auto-animation via Fokker-Planck dynamics and thresholding,” Yuan Gao, Guangzhen Jin & Jian-Guo Liu. Inverse Problems and Imaging, February, 2021, DOI: 10.3934/ipi.2021016. Online: http://www.aimsciences.org/article/doi/10.3934/ipi.2021016

Yuan Gao is the William W. Elliot Assistant Research Professor in the department of mathematics, Trinity College of Arts & Sciences.
Jian-Guo Liu is a Professor in the departments of mathematics and physics, Trinity College of Arts & Sciences.