Reversing more than a decade of flat growth in research funding, the federal budget proposal announced Wednesday includes a $2 billion increase for the National Institutes of Health, the major source of Duke’s federal research funding. The increase would bring NIH’s budget to $32.1 billion.
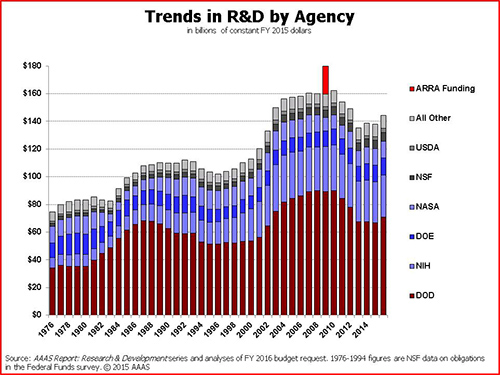
Budget trends by agency. Graph courtesy of AAAS.
The budget must pass both houses of Congress and be signed by the president to take effect, but the figures being announced are the result of negotiations between House and Senate budget committees.
According to Chris Simmons, Duke’s associate vice president for government relations, other research funds Duke relies on are also slated to increase.
The National Science Foundation’s budget would increase to $7.46 billion, up $119.3 million over 2015.
The Department of Energy’s Office of Science would grow 5.6 percent to $5.35 billion.
NASA science programs would increase 6.6 percent to $5.6 billion.
Simmons added that most of the major research accounts at the Department of Defense (Basic, Applied and Advanced Technology Development) will receive increased funding. “Unfortunately Air Force Research and DARPA will see a cut in their funding by $20 and $25 million, respectively.”
“This expansion of R&D funding is very encouraging news,” said Duke Vice Provost for Research Larry Carin. “Federal investments in university research have long been a powerful engine of the American economy and we’re heartened to see policymakers returning to that commitment.”

Long-term trends by R&D purpose. Note the little spike for the economic stimulus package. Graph courtesy of AAAS.
Within the increased NIH funding, the budget includes $200 million for the Precision Medicine Initiative, a $350 million increase for Alzheimer’s disease research and an $85 million increase for the BRAIN Initiative.
“Duke has strong research positions in all three of these areas, so we’re pleased by those particular expansions,” Carin said. “Now, of course, our faculty will have to get out there and write the grants that bring that money to North Carolina.”
Post by Karl Leif Bates