“Israeli Mass Slaughter.” “Is Joe Biden Fit to be President?” Each time we log on to social media, potent headlines encircle us, as do the unwavering and charged opinions that fill the comment spaces. Each like, repost, or slight interaction we have with social media content is devoured by the “algorithm,” which tailors the space to our demonstrated beliefs.
Founded in 2018, the lab’s 40 scholars enact cutting edge research on politics and social media. This unique intersection requires a diverse team, evident in its composition of seven different disciplines and career stages. The research has proven valuable: beneficiaries include government policy-makers, non-profit organizations, and social media companies.
The lab’s recent research project sought to probe the underlying mechanisms of our digital echo-chambers: environments where we only connect with like-minded individuals. Do we have the power to shatter the glass and expand perspectives? Researchers used bots to generate social media content of opposing party views. The content was intermixed with subject’s typical feeds, and participants were evaluated to see if their views would gradually moderate.
The results demonstrated that the more people paid attention to the bots, the more grounded in their viewpoints or polarized they became.
Clicking the iconic Twitter bird or new “X” logo signifies a step onto the battlefield, where posts are ambushed by a flurry of rebuttals upon release.
Chris Bail, Professor of Political and Data Science, shared that 90% of these tweets are generated by a meager 6% of Twitter’s users. Those 6% identify as either very liberal or very conservative, rarely settling in a midde area. Their commitment to propagating their opinions is rewarded by the algorithm, which thrives on engagement. When reactive comments filter in, the post is boosted even more. The result is a distorted perception of social media’s community, when in truth the bulk of users are moderate and watching on the sidelines.
Can this be changed? Bail described the exploration of incentives for social media users. This means rewarding both sides, fighting off the “trolls” who wreak havoc on public forums. Enter a new strategy: using bots to retweet top content creators that receive engagement from both parties.
X’s (formerly Twitter’s) Community Notes feature allows users to annotate tweets that they find misleading. This strategy includes boosting notes that annotate bipartisan creators, after finding that notes tended towards the polarized tweets.
The results were hard to ignore: misinformation decreased by 25-35%, said Bail, saving companies millions of dollars.
Social media is democracy’s public square
Christopher bail
Instead of simply bashing younger generation’s fixation on social media, Bail urged the audience to consider the bigger picture.
“What do we want to get out of social media?” “
What’s the point and how can it be made more productive?”
On a mission to answer these questions, the Polarization Lab has set out to develop evidence-based social media by creating custom platforms. In order to test the platforms out, researchers prompted A.I. to create “digital twins” of real people, to simulate users.
Co-Director Alex Volfovsky described the thought process that led to this idea: Running experiments on existing social media often requires dumping data into an A.I. system and interpreting results. But by building an engaging social network, researchers were able to manipulate conditions and observe causal effects.
How can the presence of a “like button” or “repost” feature affect our activity on platforms? On LinkedIn, even tweaking recommended users showed that people gain the most value from semi-distant connections.
In this exciting new field, unanswered questions ring loud. It can be frightening to place our trust in ambiguous algorithms for content moderation, especially when social media usage is at an all-time high.
After all, the media I consume has clearly trickled into my day-to-day decisions. I eat at restaurants I see on my Instagram feed, I purchase products that I see influencers promote, and I tend to read headlines that are spoon-fed to me. As a frequent social media user, I face the troubling reality of being susceptible to manipulation.
Amidst the fear, panelists stress that their research will help create a safer and more informed culture surrounding social media in pressing efforts to preserve democracy.
Last Tuesday, October 10 was World Mental Health Day. To mark the holiday, the Duke Institute for Brain Sciences, in partnership with other student wellness organizations, welcomed Dr. Megan Jones Bell, PsyD, the clinical director of consumer and mental health at Google, to discuss mental health. Bell was formerly chief strategy and science officer at Headspace and helped guide Headspace through its transformation from a meditation app into a comprehensive digital mental health platform, Headspace Health. Bell also founded one of the first digital mental health start-ups, Lantern, where she pioneered blended mental health interventions leveraging software and coaching. In her conversation with Dr. Murali Doraiswamy, Duke professor of psychiatry and behavioral sciences, and Thomas Szigethy, Associate Dean of Students and Director of Duke’s Student Wellness Center, Bell revealed the actions Google is taking to improve the health of the billions of people who use their platform.
She began by defining mental health, paraphrasing the World Health Organization’s definition. She said, “Mental health, to me, is a state of wellbeing in which the individual realizes his or her or their own abilities, can cope with the normal stresses of life, work productively and fruitfully, and can contribute to their own community.” Rather than taking a medicalized approach to mental health, she argued, mental health should be recognized as something that we all have. Critically, she said that mental health is not just mental disorders; the first step to improving mental health is recognition and upstream intervention.
Underlining the critical role Google plays in global mental health, Bell cited multiple statistics: three out of four people turn to the internet first for health information. On Google Search, there are 100 million searches on health everyday; Youtube boasts 25 billion views of mental health content. Given their billions of users, Bell intimated Google’s huge responsibility to provide people with accurate, authoritative, and empathetic information. The company has multiple goals in terms of mental health that are specific to different communities. There are three principal audiences that Bell described Google’s goals for: consumers, caregivers, and communities.
Google’s consumer-facing focus is providing access to high quality information and tools to manage their users’ health. With regards to caregivers, Google strives to create strong partnerships to create solutions to transform care delivery. In terms of community health, the company works with public health organizations worldwide, focusing on social determinants of health and aiming to open up data and insights to the public health community.
Szigethy followed by launching a discussion of Google’s efforts to protect adolescents. He referenced the growing and urgent mental health crisis amongst adolescents; what is Google doing to protect them?
Bell mentioned multiple projects across different platforms in order to provide youth with safer online experiences. Key to these projects is the desire to promote their mental health by default. On Google Search, this takes the form of the SafeSearch feature. SafeSearch is on by default, filtering out explicit or inappropriate results. On Youtube, default policies include various prevention measures, one of which automatically removes content that is considered “immitable.” Bell used the example of disordered eating content in order to explain the policy– in accordance with their prevention approach, YouTube removes dangerous eating-related content containing anything that the viewer can copy. YouTube also has age-restricted videos, unavailable to users under 18, as well as certain product features that can be blocked. Google also created an eating disorder hotline with experts online 24/7.
Jokingly, Bell assured the Zoom audience that Google wouldn’t be creating a therapist chatbot anytime soon — she asserted that digital tools are not “either or.” When the conversation veered towards generative AI, Bell admitted that AI has enormous potential for helping billions of people, but maintained that it needs to be developed in a responsible way. At Google, the greatest service AI provides is scalability. Google.org, Bell said, recently worked with The Trevor Project and ReflexAI on a crisis hotline for veterans called HomeTeam. Google used AI that stimulated crises to help scale up training for volunteers. Bell said, “The human is still on the other side of the phone, and AI helped achieve that”.
Next, Bell tackled the question of health information and misinformation– what she called a significant area of focus for Google. Before diving in, however, Bell clarified, “It’s not up to Google to decide what is accurate and what is not accurate.” Rather, she said that anchoring to trusted organizations is critical to embedding mental health into the culture of a community. When it comes to health information and misinformation, Bell encapsulated Google’s philosophy in this phrase: “define, operationalize, and elevate high quality information.” In order to combat misinformation on their platform, Google asked the National Academy of Medicine to help define what accurate medical sources are. The Academy then put together a framework of authoritative health info, which WHO then nationalized. YouTube then launched its “health sources” feature, where videos from the framework are the first thing that you see. In effect, the highest quality information is raised to the top of your page when you make a search. Videos in this framework also have a visible badge on the watch panel that features a phrase like “from a healthcare professional” or “from an organization with a healthcare professional.” Bell suggested that this also helps people to remember where their information is coming from, acting as a guardrail in itself. Additionally, Google continues to fight medical misinformation with an updated medical misinformation policy, which enables them to remove content that is contradictory to medical authorities or medical consensus.
Near the end of the conversation, Szigethy asked Bell if she would recommend any behaviors for embracing wellbeing. A prevention researcher by background, Bell stressed the importance of early and regular action. Our biggest leverage point for changing mental health, she asserted, is upstream intervention and embracing routines that foster our mental health. She breaks these down into five dimensions of wellbeing: mindfulness, sleep, movement and exercise, nutrition, and social connection. Her advice is to ask the question: what daily/weekly routines do I have that foster each of these? Make a list, she suggests, and try to incorporate a daily routine that addresses each of the five dimensions.
Before concluding, Bell advocated that the best thing that we can do is to approach mental health issues with humility and listen to a community first. She shared that, at Headspace, her team worked with the mayor’s office and community organizations in Hartford, Connecticut to co-define their mental health goals and map the strengths and assets of the community. Then, they could start to think about how to contextualize Headspace in that community. Bell graciously entered the Duke community with the same humility, and her conversation was a wonderful commemoration of World Mental Health Day.
Statistics and computer science double major Jenny Huang (T’23) started Duke as many of us do – vaguely pre-med, undecided on a major – but she knew she had an interest in scientific research. Four years later, with a Quad Fellowship and an acceptance to MIT for her doctoral studies, she reflects on how research shaped her time at Duke, and how she hopes to impact research.
Jenny Huang (T’23)
What is it about statistics? And what is it about research?
With experience in biology research during high school and during her first year at Duke, Huang toyed with the idea of an MD/PhD, but ultimately realized that she might be better off dropping the MD. “I enjoy figuring out how the world works” Huang says, and statistics provided a language to examine the probabilistic and often unintuitive nature of the world around us.
In another life, Huang remarked, she might have been a physics and philosophy double major, because physics offers the most fundamental understanding of how the world works, and philosophy is similar to scientific research: in both, “you pursue the truth through cyclic questioning and logic.” She’s also drawn to engineering, because it’s the process of dissecting things until you can “build them back up from first principles.”
At the International Society for Bayesian Analysis summer conference in Montreal
Huang’s research and the impact of COVID-19
For Huang, research started her first year at Duke, on a Data+ team, led by Professor Charles Nunn, studying the variation of parasite richness across primate species. To map out what types of parasites interacted with what type of monkeys, the team relied on predictors such as body mass, diet, and social activity, but in the process, they came up against an interesting phenomenon.
It appeared that the more studied a primate was, the more interactions it would have with parasites, simply because of the amount of information available on the primate. Due to geographic and experimental constraints, however, a large portion of the primate-parasite network remained understudied. This example of a concept in statistics known as sampling bias was muddling their results. One day, while making an offhand remark about the problem to one of her professors (Professor David Dunson), Huang ended up arranging a serendipitous research match. It turned out that Dunson had a statistical model that could be applied to the problem Nunn and the Data+ team were facing.
The applicability of statistics to a variety of different fields enamored Huang. When COVID-19 hit, it impacted all of us to some degree, but for Huang, it provided the perfect opportunity to apply mathematical models to a rapidly-changing pandemic. For the past two summers, through work with Dunson on a DOMath project, as well as Professor Jason Xu and Professor Rick Durrett, Huang has used mathematical modeling to assess changes in the spread of COVID-19.
On inclusivity in research
As of 2018, just 28% of graduates in mathematics and statistics at the doctoral level identified as women. Huang will eventually be included in this percentage, seeing as she begins her Ph.D. at MIT’s Department of Electrical Engineering and Computer Science in the fall, working with Professor Tamara Broderick.
“When I was younger, I always thought that successful and smart people in academia were white men,” Huang laughed. But that’s not true, she emphasizes: “it’s just that we don’t have other people in the story.” As one of the few female-presenting people in her research meetings, Huang has often felt pressure to underplay her more, “girly” traits to fit in. But interacting with intelligent, accomplished female-identifying academics in the field (including collaborations with Professor Cynthia Rudin) reaffirms to her that it’s important to be yourself: “there’s a place for everyone in research.”
At the Joint Statistical Meetings Conference in D.C with fellow researcher Gaurav Parikh
Advice for first-years and what the future holds
While she can’t predict where exactly she’ll end up, Huang is interested in taking a proactive role in shaping the impacts of artificial intelligence and machine learning on society. And as the divide between academia and industry is becoming more and more gray, years from now, she sees herself existing somewhere in that space.
Her advice for incoming Duke students and aspiring researchers is threefold. First, Huang emphasizes the importance of mentorship. Having kind and validating mentors throughout her time at Duke made difficult problems in statistics so much more approachable for her, and in research, “we need more of that type of person!”
Second, she says that “when I first approached studying math, my impatience often got in the way of learning.” Slowing down with the material and allowing herself the time to learn things thoroughly helped her improve her academic abilities.
Being around people who have this shared love and a deep commitment for their work is just the human endeavor at its best.
Jenny huang
Lastly, she stresses the importance of collaboration. Sometimes, Huang remarked,“research can feel isolating, when really it is very community-driven.” When faced with a tough problem, there is nothing more rewarding than figuring it out together with the help of peers and professors. And she is routinely inspired by the people she does research with: “being around people who have this shared love and a deep commitment for their work is just the human endeavor at its best.”
Post by Meghna Datta, Class of 2023
(Editor’s note: This is Jenny’s second appearance on the blog. As a senior at NC School of Science and Math, she wrote a post about biochemist Meta Kuehn.)
Black-capped chickadees have an incredible ability to remember where they’ve cached food in their environments. They are also small, fast, and able to fly.
So how exactly can a neuroscientist interested in their memories conduct studies on their brains? Dmitriy Aronov, Ph.D., a neuroscientist at the Zuckerman Mind Brain Behavior Institute at Columbia University, visited Duke recently to talk about chickadee memory and the practicalities of studying wild birds in a lab.
Black-capped chickadees, like many other bird species, often store food in hiding places like tree crevices. This behavior is called caching, and the ability to hide food in dozens of places and then relocate it later represents an impressive feat of memory. “The bird doesn’t get to experience this event happening over and over again,” Aronov says. It must instantly form a memory while caching the food, a process that relies on episodic memory. Episodic memory involves recalling specific experiences from the past, and black-capped chickadees are “champions of episodic memory.”
They have to remember not just the location of cached food but also other features of each hiding place, and they often have only moments to memorize all that information before moving on. According to Aronov, individual birds are known to cache up to 5,000 food items per day! But how do they do it?
Chickadees, like humans, rely on the brain’s hippocampus to form episodic memories, and the hippocampus is considerably bigger in food-caching birds than in birds of similar size that aren’t known to cache food. Aronov and his team wanted to investigate how neural activity represents the formation and retrieval of episodic memories in black-capped chickadees.
Step one: find a creative way to study food-caching in a laboratory setting. Marissa Applegate, a graduate student in Aronov’s lab, helped design a caching arena “optimized for chickadee ergonomics,” Aronov says. The arenas included crevices covered by opaque flaps that the chickadees could open with their toes or beaks and cache food in. The chickadees didn’t need any special training to cache food in the arena, Aronov says. They naturally explore crevices and cache surplus food inside.
Once a flap closed over a piece of cached food (sunflower seeds), the bird could no longer see inside—but the floor of each crevice was transparent, and a camera aimed at the arena from below allowed scientists to see exactly where birds were caching seeds. Meanwhile, a microdrive attached to the birds’ tiny heads and connected to a cable enabled live monitoring of their brain activity, down to the scale of individual neurons.
An artistic rendering of one of the cache sites in an arena. “Arenas in my lab have between 64 and 128 of these sites,” Aronov says. Drawing by Julia Kuhl.
Through a series of experiments, Aronov and his team discovered that “the act of caching has a profound effect on hippocampal activity,” with some neurons becoming more active during caching and others being suppressed. About 35% percent of neurons that are active during caching are consistently either enhanced or suppressed during caching—regardless of which site a bird is visiting. But the remaining 65% of variance is site-specific: “every cache is represented by a unique pattern of this excess activity in the hippocampus,” a pattern that holds true even when two sites are just five centimeters apart—close enough for a bird to reach from one to another.
Chickadees could hide food in any of the sites for retrieval at a future time. The delay period between the caching phase (when chickadees could store surplus food in the cache sites) and the retrieval phase (when chickadees were placed back in the arena and allowed to retrieve food they had cached earlier) ranged from a few minutes to an hour. When a bird returned to a cache to retrieve food, the same barcode-like pattern of neural activity reappeared in its brain. That pattern “represents a particular experience in a bird’s life” that is then “reactivated” at a later time.
Aronov said that in addition to caching and retrieving food, birds often “check” caching sites, both before and after storing food in them. Of course, as soon as a bird opens one of the flaps, it can see whether or not there’s food inside. Therefore, measuring a bird’s brain activity after it has lifted a flap makes it impossible to tell whether any changes in brain activity when it checks a site are due to memory or just vision. So the researchers looked specifically at neural activity when the bird first touched a flap—before it had time to open it and see what was inside. That brain activity, as it turns out, starts changing hundreds of milliseconds before the bird can actually see the food, a finding that provides strong evidence for memory.
What about when the chickadees checked empty caches? Were they making a memory error, or were they intentionally checking an empty site—even knowing it was empty—for their own mysterious reasons? On a trial-by-trial basis, it’s impossible to know, but “statistically, we have to invoke memory in order to explain their behavior,” he said.
A single moment of caching, Aronov says, is enough to create a new, lasting, and site-specific pattern. The implications of that are amazing. Chickadees can store thousands of moments across thousands of locations and then retrieve those memories at will whenever they need extra food.
It’s still unclear how the retrieval process works. From Aronov’s study, we know that chickadees can reactivate site-specific brain activity patterns when they see one of their caches (even when they haven’t yet seen what’s inside). But let’s say a chickadee has stored a seed in the bark of a particular tree. Does it need to see that tree in order to remember its cache site there? Or can it be going about its business on the other side of the forest, suddenly decide that it’s hungry for a seed, and then visualize the location of its nearest cache without actually being there? Scientists aren’t sure.
If you’re a doe-eyed first-year at Duke who wants to eventually become a doctor, chances are you are currently, or will soon, take part in a pre-med rite of passage: finding a lab to research in.
Most pre-meds find themselves researching in the fields of biology, chemistry, or neuroscience, with many hoping to make research a part of their future careers as clinicians. Undergraduate student and San Diego native Eden Deng (T’23) also found herself plodding a similar path in a neuroimaging lab her freshman year.
Eden Deng T’23
At the time, she was a prospective neuroscience major on the pre-med track. But as she soon realized, neuroimaging is done through fMRI. And to analyze fMRI data, you need to be able to conduct data analysis.
This initial research experience at Duke in the Martucci Lab, which looks at chronic pain and the role of the central nervous system, sparked a realization for Deng. “Ninety percent of my time was spent thinking about computational and statistical problems,” she explained to me. Analysis was new to her, and as she found herself struggling with it, she thought to herself, “why don’t I spend more time getting better at that academically?”
Deng at the Martucci Lab
This desire to get better at research led Deng to pursue a major in Statistics with a secondary in Computer Science, while still on the pre-med track. Many people might instantly think about how hard it must be to fit in so much challenging coursework that has virtually no overlap. And as Deng confirmed, her academic path not been without challenges.
For one, she’s never really liked math, so she was wary of getting into computation. Additionally, considering that most Statistics and Computer Science students want to pursue jobs in the technology industry, it’s been hard for her to connect with like-minded people who are equally familiar with computers and the human body.
“I never felt like I excelled in my classes,” Deng said. “And that was never my intention.” Deng had to quickly get used to facing what she didn’t know head-on. But as she kept her head down, put in the work, and trusted that eventually she would figure things out, the merits of her unconventional academic path started to become more apparent.
Research at the intersection of data and health
Last summer, Deng landed a summer research experience at Mount Sinai, where she looked at patient-level cancer data. Utilizing her knowledge in both biology and data analytics, she worked on a computational screener that scientists and biologists could use to measure gene expression in diseased versus normal cells. This will ultimately aid efforts in narrowing down the best genes to target in drug development. Deng will be back at Mount Sinai full-time after graduation, to continue her research before applying to medical school.
Deng presenting on her research at Mount Sinai
But in her own words, Deng’s most favorite research experience has been her senior thesis through Duke’s Department of Biostatistics and Bioinformatics. Last year, she reached out to Dr. Xiaofei Wang, who is part of a team conducting a randomized controlled trial to compare the merits of two different lung tumor treatments.
Generally, when faced with lung disease, the conservative approach is to remove the whole lobe. But that can pose challenges to the quality of life of people who are older, with more comorbidities. Recently, there has been a push to focus on removing smaller sections of lung tissue instead. Deng’s thesis looks at patient surgical data over the past 15 years, showing that patient survival rates have improved as more of these segmentectomies – or smaller sections of tissue removal – have become more frequent in select groups of patients.
“I really enjoy working on it every week,” Deng says about her thesis, “which is not something I can usually say about most of the work I do!” According to Deng, a lot of research – hers included – is derived from researchers mulling over what they think would be interesting to look at in a silo, without considering what problems might be most useful for society at large. What’s valuable for Deng about her thesis work is that she’s gotten to work closely with not just statisticians but thoracic surgeons. “Originally my thesis was going to go in a different direction,” she said, but upon consulting with surgeons who directly impacted the data she was using – and would be directly impacted by her results – she changed her research question.
The merits of an interdisciplinary academic path
Deng’s unique path makes her the perfect person to ask: is pursuing seemingly disparate interests, like being a Statistics and Computer Science double-major on the pre-med, track worth it? And judging by Deng’s insights, the answer is a resounding yes.
At Duke, she says, “I’ve been challenged by many things that I wouldn’t have expected to be able to do myself” – like dealing with the catch-up work of switching majors and pursuing independent research. But over time she’s learned that even if something seems daunting in the moment, if you apply yourself, most, if not all things, can be accomplished. And she’s grateful for the confidence that she’s acquired through pursuing her unique path.
Moreover, as Deng reflects on where she sees herself – and the field of healthcare – a few years from now, she muses that for the first time in the history of healthcare, a third-party player is joining the mix – technology.
While her initial motivation to pursue statistics and computer science was to aid her in research, “I’ve now seen how its beneficial for my long-term goals of going to med school and becoming a physician.” As healthcare evolves and the introduction of algorithms, AI and other technological advancements widens the gap between traditional and contemporary medicine, Deng hopes to deconstruct it all and make healthcare technology more accessible to patients and providers.
“At the end of the day, it’s data that doctors are communicating to patients,” Deng says. So she’s grateful to have gained experience interpreting and modeling data at Duke through her academic coursework.
And as the Statistics major particularly has taught her, complexity is not always a good thing – sometimes, the simpler you can make something, the better. “Some research doesn’t always do this,” she says – she’s encountered her fair share of research that feels performative, prioritizing complexity to appear more intellectual. But by continually asking herself whether her research is explainable and applicable, she hopes to let those two questions be the North Stars that guide her future research endeavors.
At the end of the day, it’s data that doctors are communicating to patients.
Eden Deng
When asked what advice she has for first-years, Deng said that it’s important “to not let your inexperience or perceived lack of knowledge prevent you from diving into what interests you.” Even as a first-year undergrad, know that you can contribute to academia and the world of research.
And for those who might be interested in pursuing an academic path like Deng, there’s some good news. After Deng talked to the Statistics department about the lack of pre-health representation that existed, the Statistics department now has a pre-health listserv that you can join for updates and opportunities pertaining specifically to pre-med Stats majors. And Deng emphasizes that the Stats-CS-pre-med group at Duke is growing. She’s noticed quite a few underclassmen in the Statistics and Computer Science departments who vocalize an interest in medical school.
So if you also want to hone your ability to communicate research that you care about – whether you’re pre-med or not – feel free to jump right into the world of data analysis. As Deng concludes, “everyone has something to say that’s important.”
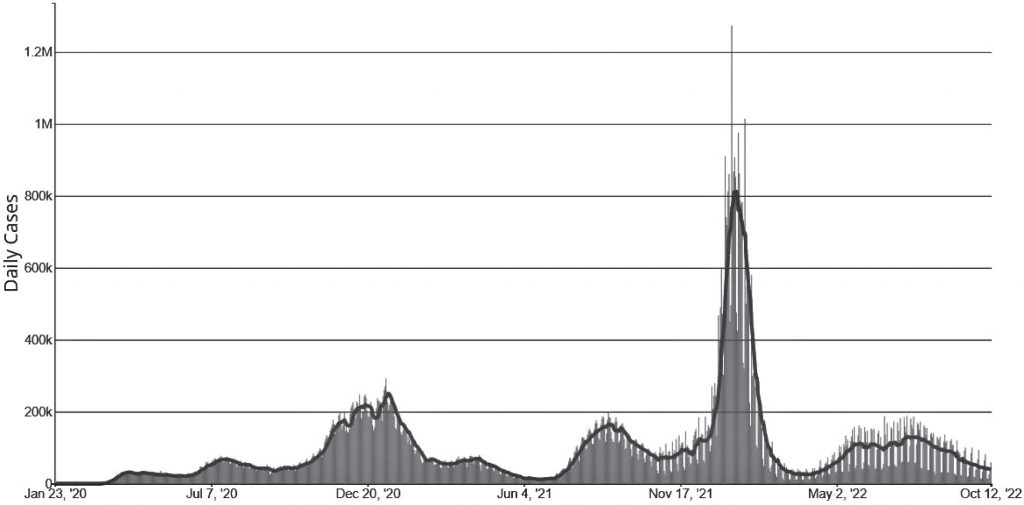
A Duke team looks at the math behind COVID’s waves as new coronavirus variants continue to emerge.Credit: @ink-drop
DURHAM, N.C. — First it was Alpha. Then Delta. Now Omicron and its alphabet soup of subvariants. In the three years since the coronavirus pandemic started, every few months or so a new strain seems to go around, only to be outdone by the next one.
If the constant rise and fall of new coronavirus variants has left you feeling dizzy, you’re not alone. But where most people see a pandemic roller coaster, one Duke team sees a mathematical pattern.
In a new study, a group of students led by Duke mathematician Rick Durrett studied the calculus behind the pandemic’s waves.
Published Nov. 2022 in the journal Proceedings of the National Academy of Sciences, their study got its start as part of an 8-week summer research program called DOmath, now known as Math+, which brings undergraduates together to collaborate on a faculty-led project.
Their mission: to build and analyze simple mathematical models to understand the spread of COVID-19 as one strain after another popped up and then rose to outcompete the others.
In an interview about their research, project manager and Duke Ph.D. student Hwai-Ray Tung pointed to a squiggly line showing the number of confirmed COVID cases per capita in the U.S. between January 2020 and October 2022.
The COVID-19 pandemic has unfolded in waves. Adapted from The New York Times, July 18, 2022
“You can see very distinct humps,” Tung said.
The COVID pandemic has unfolded in a series of surges and lulls — spikes in infection followed by downturns in case counts.
The ups and downs are partly explained by factors such as behavior, relaxation of public policies, and waning immunity from vaccines. But much of the roller coaster has been driven by changes to the coronavirus itself.
All viruses change over time, evolving mutations in their genetic makeup as they spread and replicate. Most mutations are harmless, but every so often some of them give the virus an edge: Enabling it to break into cells more easily than other strains, better evade immunity from vaccines and past infection, or make more copies of itself in order to spread more effectively.
Take the Delta variant, for example. When it first started going around in the U.S. in May 2021, it was responsible for just 1% of COVID cases. But thanks to mutations that helped the virus evade antibodies and infect cells more easily, it quickly tore across the country. Within two months it had outcompeted all the other variants and rose to the top spot, causing 94% of new infections.
“The natural question to ask is: What’s going on with the transition between these different variants?” Tung said.
For their study the team developed a simple epidemic model called an SIR model, which uses differential equations to compute the spread of disease over time.
SIR models work by categorizing individuals as either susceptible to getting sick, currently infected, or recovered. The team modified this model to have two types of infected individuals and two types of recovered individuals, one for each of two circulating strains.
The model assumes that each infectious person spreads the virus to a certain number of new people per day (while sparing others), and that, each day, a certain fraction of the currently infected group recovers.
In the study, the team applied the SIR model to data from a database called GISAID, which contains SARS-CoV-2 virus sequences from the pandemic. By looking at the coronavirus’s genetic code, researchers can tell which variants are causing infection.
Study co-author Jenny Huang ’23 pointed to a series of S-shaped curves showing the fraction of infections due to each strain from one week to the next, from January 2021 to June 2022.
When they plotted the data as points on a graph, they found that it followed a logistic differential equation as each new variant emerged, rose steeply, and — within six to 10 weeks — quickly displaced its predecessors, only to be taken over later by even more aggressive or contagious strains.
Durrett said it’s the mathematical equivalent of something biologists call a selective sweep, when natural selection increases a variant’s frequency from low to high, until nearly everyone getting stick is infected with the same strain.
“I’ve been interested in epidemic modeling since the end of freshman year when COVID started,” said Huang, a senior who plans to pursue a Ph.D. in statistics next year with support from a prestigious Quad Fellowship.
They’re not all typical math majors, Durrett said of his team. Co-author Sofia Hletko, ’25, was a walk-on to the rowing team. Laura Boyle ’24 was a Cameron Crazie.
For some team members it was their first experience with mathematical research: “I came in having no idea what a differential equation was,” Boyle said. “And by the end, I was the person in the group explaining that part of our presentation to everyone.”
Boyle says one question she keeps getting asked is: what about the next COVID surge?
“It’s very hard to say what will happen,” Boyle said.
The teams says their research can’t predict future waves. Part of the reason is the scanty data on the actual number of infections.
Countries have dialed back on their surveillance testing, and fewer places are doing the genomic sequencing necessary to identify different strains.
“We don’t know the nature of future mutations,” Durrett said. “Changes in people’s behavior will have a significant impact too.”
“The point of this paper wasn’t to predict; rather it was to explain why the waves were occurring,” Huang said. “We were trying to explain a complicated phenomenon in a simple way.”
This research was supported by a grant from the National Science Foundation (DMS 1809967) and by Duke’s Department of Mathematics.
CITATION: “Selective Sweeps in SARS-CoV-2 Variant Competition,” Laura Boyle, Sofia Hletko, Jenny Huang, June Lee, Gaurav Pallod, Hwai-Ray Tung, and Richard Durrett. Proceedings of the National Academy of Sciences, Nov. 3, 2022. DOI: 10.1073/pnas.2213879119.
DURHAM, N.C. — English professor Charlotte Sussman doesn’t get much time in her role as department chair to work on her latest book project, an edited collection of essays on migration in and out of Europe.
“At least not during daylight hours,” Sussman said.
But a recent workshop brought a welcome change to that. Sussman was one of 22 faculty who gathered Dec. 13 for an end-of-semester writing retreat hosted by the Duke Faculty Write Program.
Duke faculty and staff gather for an end-of-semester writing retreat.
Most of them know all too well the burnout faculty and students face at the end of the semester. But for a few precious hours, they hit pause on the constant onslaught of emails, meetings, grading and other duties to work alongside fellow writers.
The participants sat elbow-to-elbow around small tables in a sunlit room at the Duke Integrative Medicine Center. Some scribbled on pads of paper; others peered over their laptops.
Each person used the time to focus on a specific writing project. Sussman aimed to tackle an introduction for her 34-essay collection. Others spent the day working on a grant application, a book chapter, a course proposal, a conference presentation.
Jennifer Ahern-Dodson, Ph.D.
“We have so many negative associations with writing because there’s always something more to do,” said associate professor of the practice Jennifer Ahern-Dodson, who directs the program. “I want to change the way people experience writing.”
Ahern-Dodson encouraged the group to break their projects into small, specific tasks as they worked toward their goals. It might be reading a journal article, drafting an outline, organizing some notes, even just creating or finding a file.
After a brief workshop, she kicked off a 60-minute writing session. “Now we write!” she said.
The retreat is the latest installment in a series that Ahern-Dodson has been leading for over 10 years. In a typical week, most of these scholars wouldn’t find themselves in the same room. There were faculty and administrators from fields as diverse as history, African and African American Studies, law, psychology, classics, biostatistics. New hires sitting alongside senior scholars with decades at Duke.
Peggy Nicholson, J.D., Clinical Professor of Law, writing alongside colleagues from across campus
“I really like the diversity of the group,” said Carolyn Lee, Professor of the Practice of Asian and Middle Eastern Studies. “It’s a supportive environment without any judgement. They all have the same goal: they want to get some writing done.”
Sussman said such Faculty Write program get-togethers have been “indispensable” to bringing some of her writing projects over the finish line.
Participants say the program not only fosters productivity, but also a sense of connection and belonging. Take Cecilia Márquez, assistant professor in the Duke History Department. She joined the Duke faculty in 2019, but within months the world went into COVID-19 lockdown.
“This was my way to meet colleagues,” said Márquez, who has since started a writing group for Latinx scholars as an offshoot.
The writing retreats are free for participants, thanks to funding from the Office of the Dean of Trinity College of Arts and Sciences and the Thompson Writing Program. Participants enjoy lunch, coaching and community in what’s normally a solitary activity.
“I appreciate the culture of collaboration,” said David Landes, who came to Duke this year as Assistant Professor of the Practice in Duke’s Thompson Writing Program. “In the humanities our work is intensely individualized.”
Assistant Professor of Biostatistics & Bioinformatics Hwanhee Hong (left) and Adam Rosenblatt, Associate Professor of the Practice in International Comparative Studies (right)
Retreats are one of many forms of support offered by the Faculty Write program: there are also writing groups and workshops on topics such as balancing teaching and scholarship or managing large research projects.
“One of the distinguishing features of Faculty Write is the community that extends beyond one event,” Ahern-Dodson said. “Many retreats are reunions.”
After two hours of writing, Ahern-Dodson prompted the group to take a break. Some got up to stretch or grab a snack; others stepped outside to chat or stroll through the center’s labyrinth at the edge of Duke Forest.
It’s more than just dedicated writing time, Ahern-Dodson said. It’s also “learning how to work with the time they have.”
The retreats offer tips from behavioral psychology, writing studies, and other disciplines on time management, motivation, working with reader feedback, and other topics.
As they wrap up the last writing session of the day, Ahern-Dodson talks about how to keep momentum.
“Slow-downs and writing block are normal,” Ahern-Dodson said. Maybe how you wrote before isn’t working anymore, or you’re in a rut. Perhaps you’re not sure how to move forward, or maybe writing simply feels like a slog.
“There are some things you could try to get unstuck,” Ahern-Dodson said. Consider changing up your routine: when and where you write, or how long each writing session lasts.
“Protect your writing time as you would any other meeting,” Ahern-Dodson said.
Sharing weekly goals and accomplishments with other people can help too, she added.
“Celebrate each win.”
Ultimately, Ahern-Dodson says, the focus is not on productivity but on meaning, progress and satisfaction over time.
“It’s all about building a sustainable writing practice,” she said.
Ahern-Dodson leads an end-of-semester writing retreat for Duke scholars.
Coming soon: On Friday, Jan. 27 from 12-1 p.m., join Vice Provost for Faculty Advancement Abbas Benmamoun for a conversation about how writing works for him as a scholar and administrator. In person in Rubenstein Library 249 (Carpenter Fletcher Room)
Get Involved: Faculty and staff are invited to sign up for writing groups for spring 2023 here.
The healthcare industry and academic medicine are excited about the potential for artificial intelligence — really clever computers — to make our care better and more efficient.
The students from Duke’s Health Data Science (HDS) and AI Health Data Science Fellowship who presented their work at the 2022 Duke AI Health Poster Showcase on Dec. 6 did an excellent job explaining their research findings to someone like me, who knows very little about artificial intelligence and how it works. Here’s what I learned:
Artificial intelligence is a way of training computer systems to complete complex tasks that ordinarily require human thinking, like visual categorization, language translation, and decision-making. Several different forms of artificial intelligence were presented that do healthcare-related things like sorting images of kidney cells, measuring the angles of a joint, or classifying brain injury in CT scans.
Talking to the researchers made it clear that this technology is mainly intended to be supplemental to experts by saving them time or providing clinical decision support.
Meet Researcher Akhil Ambekar
Akhil standing next to his poster “Glomerular Segmentation and Classification Pipeline Using NEPTUNE Whole Slide Images”
Akhil Ambekar and team developed a pipeline to automate the classification of glomerulosclerosis, or scarring of the filtering part of the kidneys, using microscopic biopsy images. Conventionally, this kind of classification is done by a pathologist. It is time-consuming and limited in terms of accuracy and reproducibility of observations. This AI model was trained by providing it with many questions and corresponding answers so that it could learn how to correctly answer questions. A real pathologist oversaw this work, ensuring that the computer’s training was accurate.
Akil’s findings suggest that this is a feasible approach for machine classification of glomerulosclerosis. I asked him how this research might be used in medicine and learned that a program like this could save expert pathologists a lot of time.
What was Akhil’s favorite part of this project? Engaging in research, experimenting with Python and running different models, trying to find what works best.
Meet Researcher Irene Tanner
Irene Tanner and her poster, “Developing a Deep Learning Pipeline to Measure the Hip-Knee-Ankle Angle in Full Leg Radiographs”
The research Irene Tanner and her team have done aims to develop a deep learning-based pipeline to calculate hip-knee-ankle angles from full leg x-rays. This work is currently in progress, but preliminary results suggest the model can precisely identify points needed to calculate the angles of hip to knee to ankle. In the future, this algorithm could be applied to predict outcomes like pain and physical function after a patient has a joint replacement surgery.
What was Irene’s favorite part of this project? Developing a relationship with mentor, Dr. Maggie Horn, who she said provided endless support whenever help was needed.
Meet Researcher Brian Lerner
Brian Lerner and his poster, “Using Deep Learning to Classify Traumatic Brain Injury in CT Scans”
Brian Lerner and his team investigated the application of deep learning to standardize and sharpen diagnoses of traumatic brain injury (TBI) from Computerized Tomography (CT) scans of the brain. Preliminary findings suggest that the model used (simple slice) is likely not sufficient to capture the patterns in the data. However, future directions for this work might examine how the model could be improved. Through this project, Brian had the opportunity to shadow a neurologist in the ER and speculated upon many possibilities for the use of this research in the field.
What was Brian’s favorite part of this project? Shadowing neurosurgeon Dr. Syed Adil at Duke Hospital and learning what the real-world needs for this science are.
Many congratulations to all who presented at this year’s AI Health Poster Showcase, including the many not featured in this article. A big thanks for helping me to learn about how AI Health research might be transformative in answering difficult problems in medicine and population health.
Saxicolous lichens (lichens that grow on stones) from the Namib Desert, and finger lichen, Dactylina arctica (bottom left insert), common in the Arctic, on display in Dr. Jolanta Miadlikowska’s office. The orange color on some of the lichen comes from metabolites, or secondary chemicals produced by different lichen species. The finger lichen is hollow.
Lichens are everywhere—grayish-green patches on tree bark on the Duke campus, rough orange crusts on desert rocks, even in the Antarctic tundra. They are “pioneer species,” often the first living things to return to barren, desolate places after an extreme disturbance like a lava flow. They can withstand extreme conditions and survive where nearly nothing else can. But what exactly are lichens, and why does Duke have 160,000 of them in little envelopes? I reached out to Dr. Jolanta Miadlikowska and Dr. Scott LaGreca, two lichen researchers at Duke, to learn more.
Dr. Jolanta Miadlikowska looking at lichen specimens under a dissecting microscope. The pale, stringy lichen on the brown bag is whiteworm lichen (Thamnolia vermicularis), used to make “snow tea” in parts of China.
According to Miadlikowska, a senior researcher, lab manager, and lichenologist in the Lutzoni Lab (and one of the Instructors B for the Bio201 Gateway course) at Duke, lichens are “obligate symbiotic associations,” meaning they are composed of two or more organisms that need each other. All lichens represent a symbiotic relationship between a fungus (the “mycobiont”) and either an alga or a cyanobacterium or both (the “photobiont”). They aren’t just cohabiting; they rely on each other for survival. The mycobiont builds the thallus, which gives lichen its structure. The photobiont, on the other hand, isn’t visible—but it is important: it provides “food” for the lichen and can sometimes affect the lichen’s color. The name of a lichen species refers to its fungal partner, whereas the photobiont has its own name.
Lichen viewed through a dissecting microscope. The black speckles visible on some of the orange lichen lobes are a “lichenicolous” fungus that can grow on top of lichen. There are also “endolichenic fungi… very complex fungal communities that live inside lichen,” Miadlikowska says. “We don’t see them, but they are there. And they are very interesting.”
Unlike plants, fungi can’t perform photosynthesis, so they have to find other ways to feed themselves. Many fungi, like mushrooms and bread mold, are saprotrophs, meaning they get nutrients from organic matter in their environment. (The word “saprotroph” comes from Greek and literally means “rotten nourishment.”) But the fungi in lichens, Miadlikowska says, “found another way of getting the sugar—because it’s all about the sugar—by associating with an organism that can do photosynthesis.” More often than not, that organism is a type of green algae, but it can also be a photosynthetic bacterium (cyanobacteria, also called blue-green algae). It is still unclear how the mycobiont finds the matching photobiont if both partners are not dispersed together. Maybe the fungal spores (very small fungal reproductive unit) “will just sit and wait” until the right photobiont partner comes along. (How romantic.) Some mycobionts are specialists that “can only associate with a few or a single partner—a ‘species’ of Nostoc [a cyanobacterium; we still don’t know how many species of symbiotic and free-living Nostoc are out there and how to recognize them], for example,” but many are generalists with more flexible preferences.
Two species of foliose (leaf-like) lichens from the genus Peltigera. In the species on the left (P. canina), the only photobiont is a cyanobacterium from the genus Nostoc, making it an example of bi-membered symbiosis. In the species on the right (P.aphthosa), on the other hand, the primary photobiont is a green alga (which is why the thallus is so green when wet). In this case, Nostoc is a secondary photobiont contained only in the cephalodia—the dark, wart-like structures on the surface. With two photobionts plus the mycobiont, this is an example of tri-membered symbiosis.
Lichens are classified based on their overall thallus shape. They can be foliose (leaf-like), fruticose (shrubby), or crustose (forming a crust on rocks or other surfaces). Lichens that grow on trees are epiphytic, while those that live on rocks are saxicolous; lichens that live on top of mosses are muscicolous, and ground-dwelling lichens are terricolous. Much of Miadlikowska’s research is on a group of cyanolichens (lichens with cyanobacteria partners) from the genus Peltigera. She works on the systematics and evolution of this group using morphology-, anatomy-, and chemistry-based methods and molecular phylogenetic tools. She is also part of a team exploring biodiversity, ecological rules, and biogeographical patterns in cryptic fungal communities associated with lichens and plants (endolichenic and endophytic fungi). She has been involved in multiple ongoing NSF-funded projects and also helping graduate students Ian, Carlos, Shannon, and Diego in their dissertation research. She spent last summer collecting lichens with Carlos and Shannon and collaborators in Alberta, Canada and Alaska. If you walk in the sub basement of the Bio Sciences building where Bio201 and Bio202 labs are located, check out the amazing photos of lichens (taken by Thomas Barlow, former Duke undergraduate) displayed along the walls! Notice Peltigera species, including some new to science, described by the Duke lichen team.
Lichens have value beyond the realm of research, too. “In traditional medicine, lichens have a lot of use,” Miadlikowska says. Aside from medicinal uses, they have also been used to dye fabric and kill wolves. Some are edible. Miadlikowska herself has eaten them several times. She had salad in China that was made with leafy lichens (the taste, she says, came mostly from soy sauce and rice vinegar, but “the texture was coming from the lichen.”). In Quebec, she drank tea made with native plants and lichens, and in Scandinavia, she tried candied Cetraria islandica lichen (she mostly tasted the sugar and a bit of bitterness, but once again, the lichen’s texture was apparent).
In today’s changing world, lichens have another use as well, as “bioindicators to monitor the quality of the air.” Most lichens can’t tolerate air pollution, which is why “in big cities… when you look at the trees, there are almost no lichens. The bark is just naked.” Lichen-covered trees, then, can be a very good sign, though the type of lichen matters, too. “The most sensitive lichens are the shrubby ones… like Usnea,” Miadlikowska says. Some lichens, on the other hand, “are able to survive in anthropogenic places, and they just take over.” Even on “artificial substrates like concrete, you often see lichens.” Along with being very sensitive to poor air quality, lichens also accumulate pollutants, which makes them useful for monitoring deposition of metals and radioactive materials in the environment.
Dr. Scott LaGreca with some of the 160,000 lichen specimens in Duke’s herbarium.
LaGreca, like Miadlikoska, is a lichenologist. His research primarily concerns systematics, evolution and chemistry of the genus Ramalina. He’s particularly interested in “species-level relationships.” While he specializes in lichens now, LaGreca was a botany major in college. He’d always been interested in plants, in part because they’re so different from animals—a whole different “way of being,” as he puts it. He used to take himself on botany walks in high school, and he never lost his passion for learning the names of different species. “Everything has a name,” he says. “Everything out there has a name.” Those names aren’t always well-known. “Some people are plant-blind, as they call it…. They don’t know maples from oaks.” In college he also became interested in other organisms traditionally studied by botanists—like fungi. When he took a class on fungi, he became intrigued by lichens he saw on field trips. His professor was more interested in mushrooms, but LaGreca wanted to learn more, so he specialized in lichens during grad school at Duke, and now lichens are central to his job. He researches them, offers help with identification to other scientists, and is the collections manager for the lichens in the W.L. and C.F. Culberson Lichen Herbarium—all 160,000 of them.
The Duke Herbarium was founded in 1921 by Dr. Hugo Blomquist. It contains more than 825,000 specimens of vascular and nonvascular plants, algae, fungi, and, of course, lichens. Some of those specimens are “type” specimens, meaning they represent species new to science. A type specimen essentially becomes the prototype for its species and “the ultimate arbiter of whether something is species X or not.” But how are lichens identified, anyway?
Lichenologists can consider morphology, habitat, and other traits, but thanks to Dr. Chicita Culberson, who was a chemist and adjunct professor at Duke before her retirement, they have another crucial tool available as well. Culbertson created a game-changing technique to identify lichens using their chemicals, or metabolites, which are often species-specific and thus diagnostic for identification purposes. That technique, still used over fifty years later, is a form of thin-layer chromatography. The process, as LaGreca explains, involves putting extracts from lichen specimens—both the specimens you’re trying to identify and “controls,” or known samples of probable species matches—on silica-backed glass plates. The plates are then immersed in solvents, and the chemicals in the lichens travel up the paper. After the plates have dried, you can look at them under UV light to see if any spots are fluorescing. Then you spray the plates with acid and “bake it for a couple hours.” By the end of the process, the spots of lichen chemicals should be visible even without UV light. If a lichen sample has traveled the same distance up the paper as the control specimen, and if it has a similar color, it’s a match. If not, you can repeat the process with other possible matches until you establish your specimen’s chemistry and, from there, its identity. Culberson’s method helped standardize lichen identification. Her husband also worked with lichens and was a director of the Duke Gardens.
Thin-layer chromatography plates in Dr. LaGreca’s office. The technique, created by Dr. Chicita Culberson, helps scientists identify lichens by comparing their chemical composition to samples of known identity. Each plate was spotted with extracts from different lichen specimens, and then each was immersed in a different solvent, after which the chemicals in the extracts travel up the plate . Each lichen chemical travels a characteristic distance (called the “Rf value”) in each solvent. Here, the sample in column 1 on the rightmost panel matches the control sample in column 2 in terms of distance traveled up the page, indicating that they’re the same species. The sample in column 4, on the other hand, didn’t travel as far as the one in column 5 and has a different color. Therefore, those chemicals (and species) do not match.
LaGreca shows me a workroom devoted to organisms that are cryptogamic, a word meaning “hidden gametes, or hidden sex.” It’s a catch-all term for non-flowering organisms that “zoologists didn’t want to study,” like non-flowering plants, algae, and fungi. It’s here that new lichen samples are processed. The walls of the workroom are adorned with brightly colored lichen posters, plus an ominous sign warning that “Unattended children will be given an espresso and a free puppy.” Tucked away on a shelf, hiding between binders of official-looking documents, is a thin science fiction novel called “Trouble with Lichen” by John Wyndham.
The Culberson Lichen Herbarium itself is a large room lined with rows of cabinets filled with stacks upon stacks of folders and boxes of meticulously organized lichen samples. A few shelves are devoted to lichen-themed books with titles like Lichens De France and Natural History of the Danish Lichens.
Each lichen specimen is stored in an archival (acid-free) paper packet, with a label that says who collected it, where, and on what date. (“They’re very forgiving,” says LaGreca. “You can put them in a paper bag in the field, and then prepare the specimen and its label years later.”) Each voucher is “a record of a particular species growing in a particular place at a particular time.” Information about each specimen is also uploaded to an online database, which makes Duke’s collection widely accessible. Sometimes, scientists from other institutions find themselves in need of physical specimens. They’re in luck, because Duke’s lichen collection is “like a library.” The herbarium fields loan requests and trades samples with herbaria at museums and universities across the globe. (“It’s kind of like exchanging Christmas presents,” says LaGreca. “The herbarium community is a very generous community.”)
Duke’s lichen collection functions like a library in some ways, loaning specimens to other scientists and trading specimens with institutions around the world.
Meticulous records of species, whether in databases of lichens or birds or “pickled fish,” are invaluable. They’re useful for investigating trends over time, like tracking the spread of invasive species or changes in species’ geographic distributions due to climate change. For example, some lichen species that were historically recorded on high peaks in North Carolina and elsewhere are “no longer there” thanks to global warming—mountain summits aren’t as cold as they used to be. Similarly, Henry David Thoreau collected flowering plants at Walden Pond more than 150 years ago, and his samples are still providing valuable information. By comparing them to present-day plants in the same location, scientists can see that flowering times have shifted earlier due to global warming. So why does Duke have tens of thousands of dried lichen samples? “It comes down to the reproducibility of science,” LaGreca says. “A big part of the scientific method is being able to reproduce another researcher’s results by following their methodology. By depositing voucher specimens generated from research projects in herbaria like ours, future workers can verify the results” of such research projects. For example, scientists at other institutions will sometimes borrow Duke’s herbarium specimens to verify that “the species identification is what the label says it is.” Online databases and physical species collections like the herbarium at Duke aren’t just useful for scientists today. They’re preserving data that will still be valuable hundreds of years from now.
From shot-putting, to helping conduct two research studies, to being selected for a cardiology conference, meet: Kinsie Huggins. She is from Houston, Texas, currently majoring in Biology and minoring in Psychology with a Pre-Med track here at Duke. With such a simple description, one can already see how bright her future is!
“I want to be a pediatrician and work with kids,” Huggins says. “When I was younger, I lived in Kansas, and in my area, there were no black pediatricians. My mother decided to go far to find one and I really bonded with my pediatrician. One day, I made a pact with her in that I would become a pediatrician too so that I can also inspire other little girls like me of my color and other minority groups.”
Having such a passion to let African-American and minority voices be heard, Huggins is also part of the United Black Athletes, using her shot-put platform to make sure these voices are heard in the athletics department.
And while she may be a top-notch sportswoman, she is also just as impressive when it comes to her studies and research. One of her projects focuses on the field of nephrology – the study of kidneys and kidney disease. She and a pediatric nephrologist are currently working on studying rare kidney diseases and the differences in DNA correlating to these diseases.
Kinsie is also a researcher at GRID (Genomics Race Identity Difference), which studies the sickle cell trait in the NCAA. With the sudden deaths of college athletes from periods of over-exhaustion during conditioning, there has been a rise in attention of sickle cell trait and its impact on athletes. At first, the NCAA implemented a policy that made it mandatory for college athletes to get tested for sickle cell in 2010, but some were wary about the lack of scientific validity in such claims. Now, the NCAA has funded GRID to conduct such research.
The difference of Normal red blood cell and sickle cell (CDC).
“We are analyzing the policy (athletes need to be tested for sickle cell), interviewing athletes in check-ups, and looking at data to see if the policy is working out for athletes and their performance/health,” Huggins explains.
With such an impressive profile, it doesn’t go without saying that Huggins didn’t go unnoticed. The American College of Cardiology (ACC) select high school and college students interested in the field of medicine and have them attend a conference in Washington D.C. to hear about research presentations, groundbreaking results of late-breaking clinical trials, and lectures in the field. Having worked hard, Huggins was selected to be part of the Youth Scholars program from the ACC and was invited to the conference on April 2-4.
Let’s wish Kinsie the best of luck at the conference and on her future research!